
Redis第二篇-实现业务问题🌸
我的Redis笔记🍥🍥

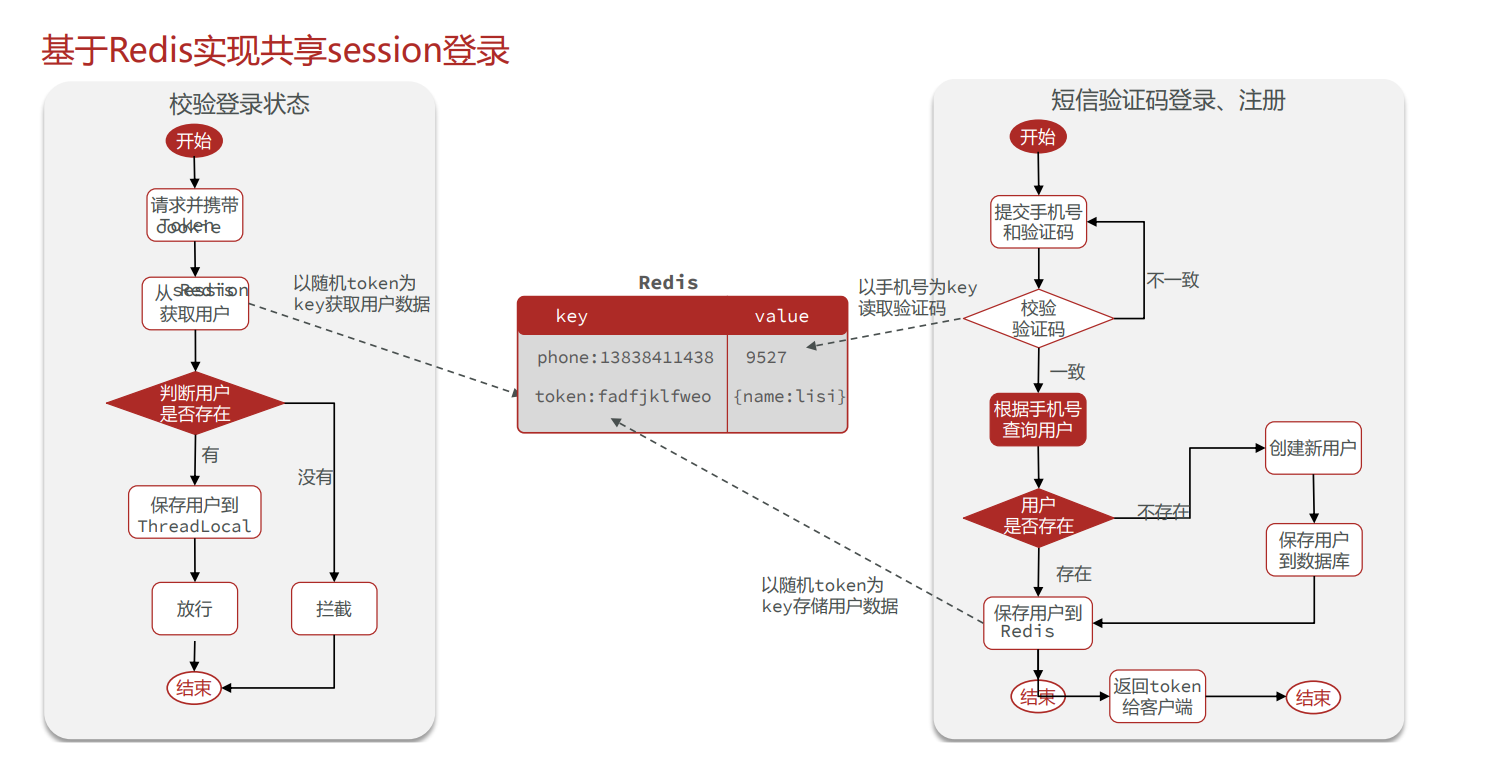
Redis实现 [短信登陆功能]
先来一个最简单的实现
pom.xml 依赖文件
<dependencies> |
图解
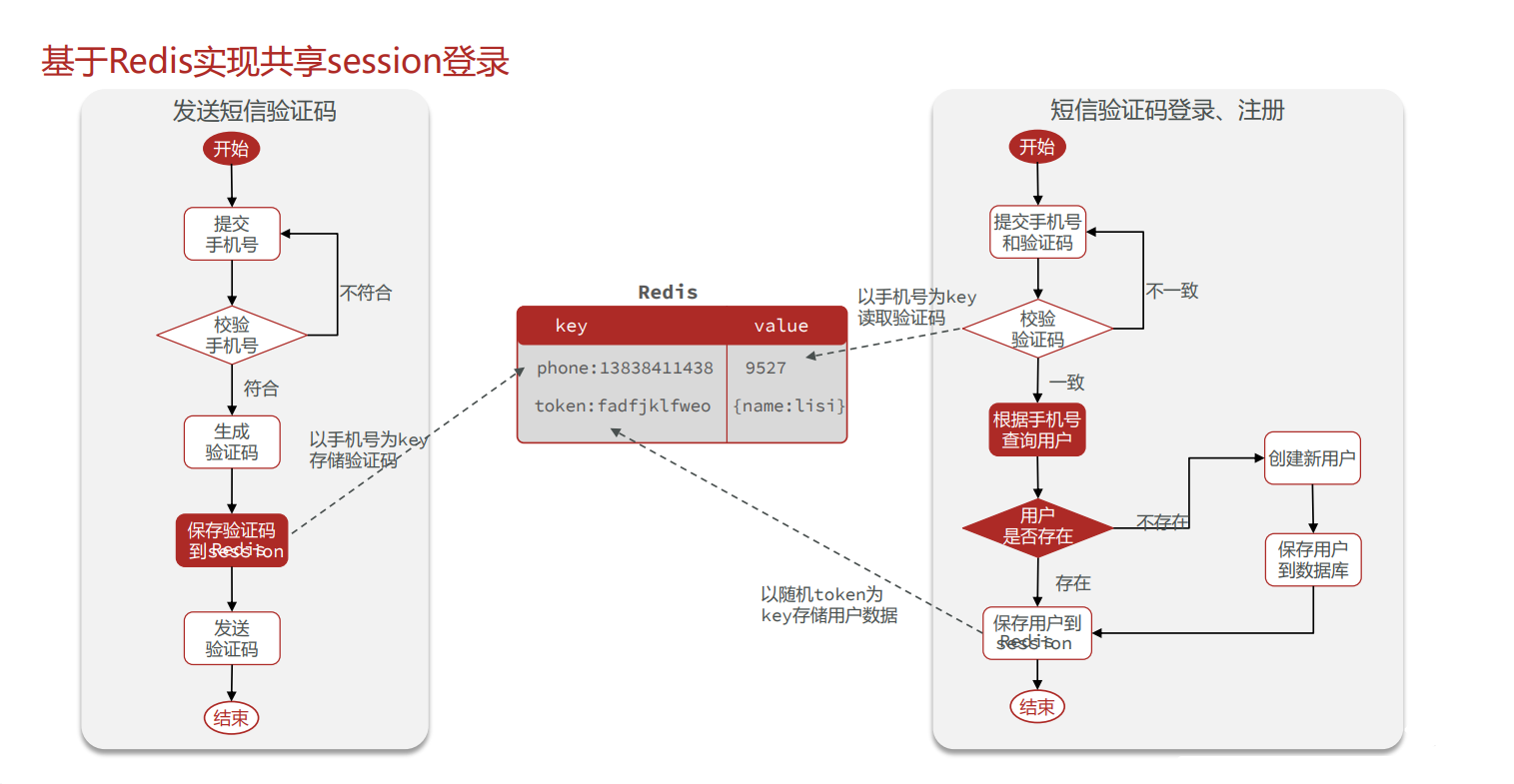
UserService 实现
package com.ayaka.service.impl; |
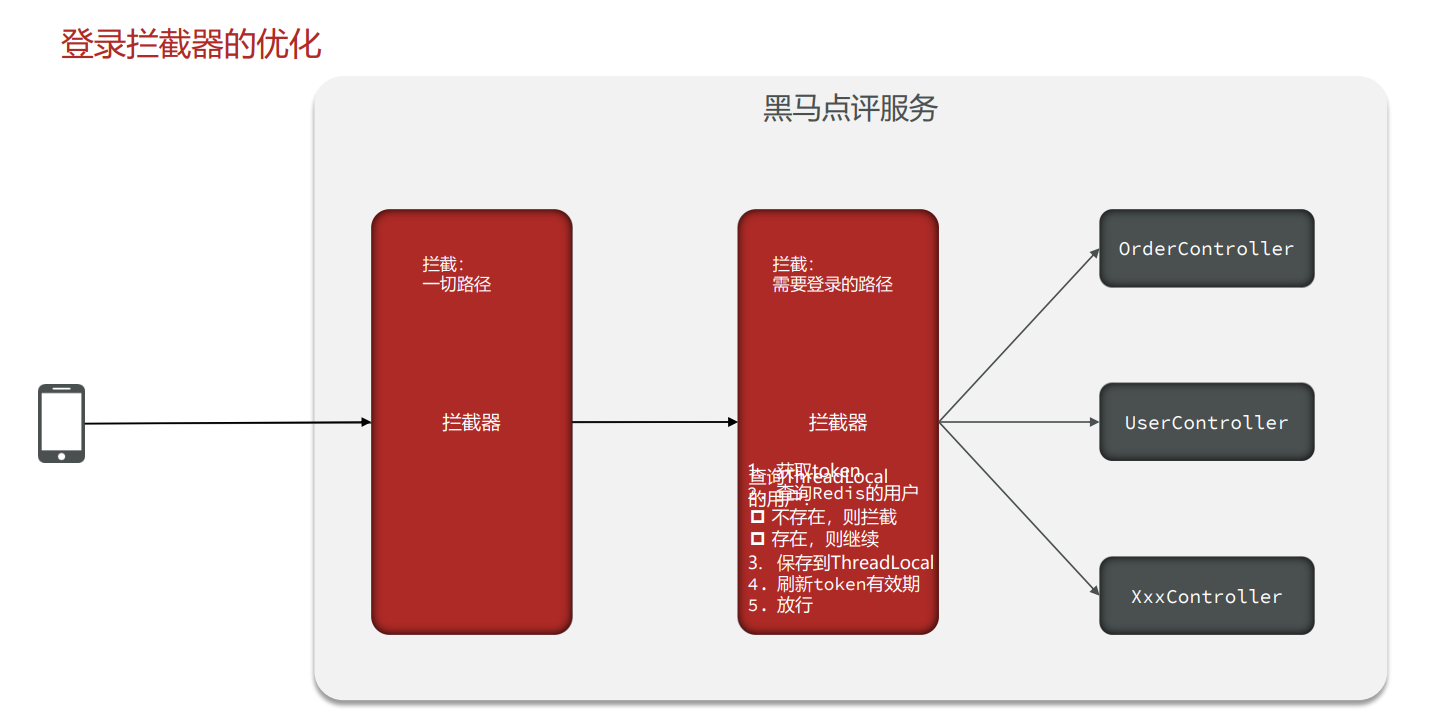
拦截器的实现
package com.ayaka.config; |
Redis解决 [缓存] [TODO]
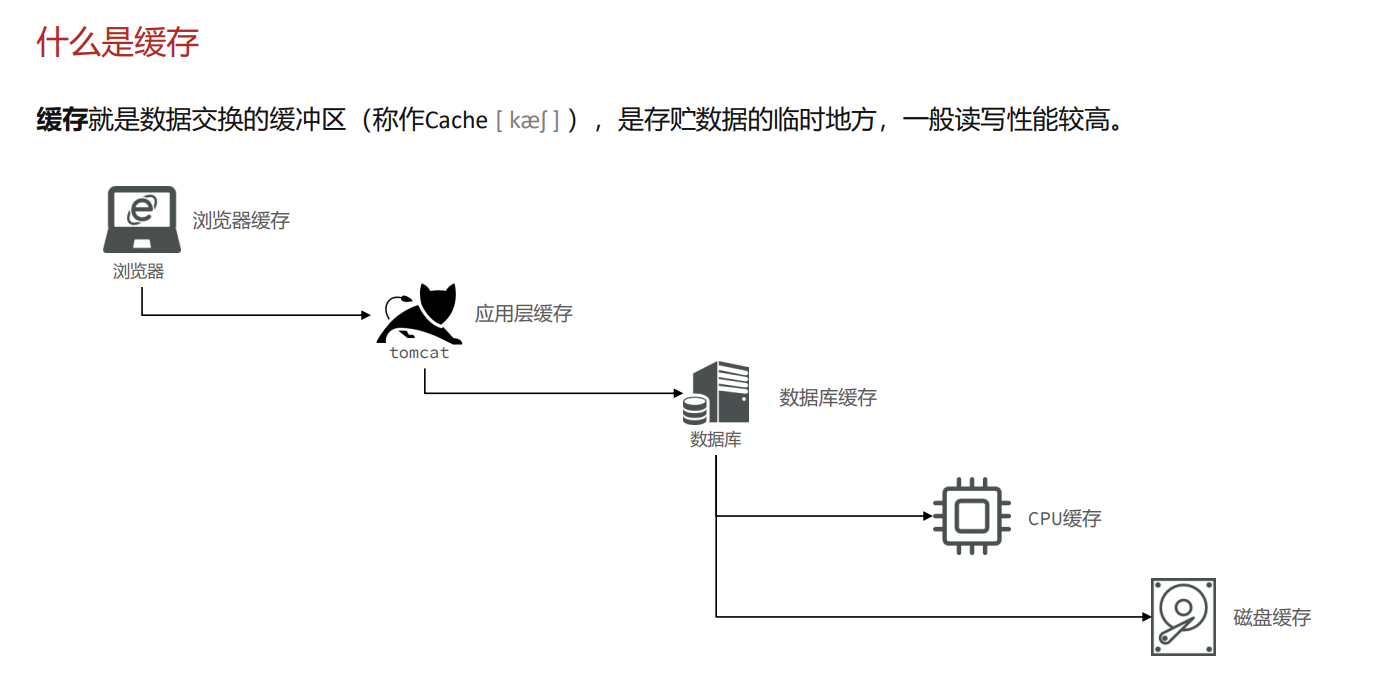
什么是缓存
缓存作用和成本
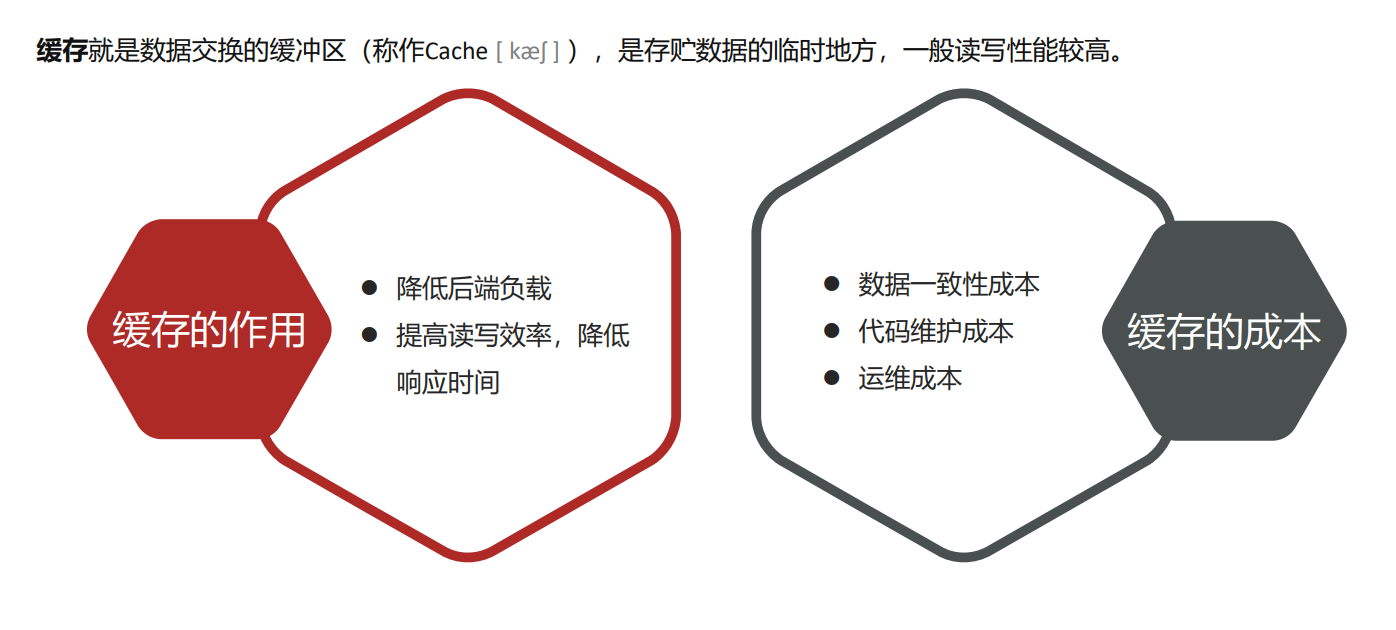
缓存更新策略
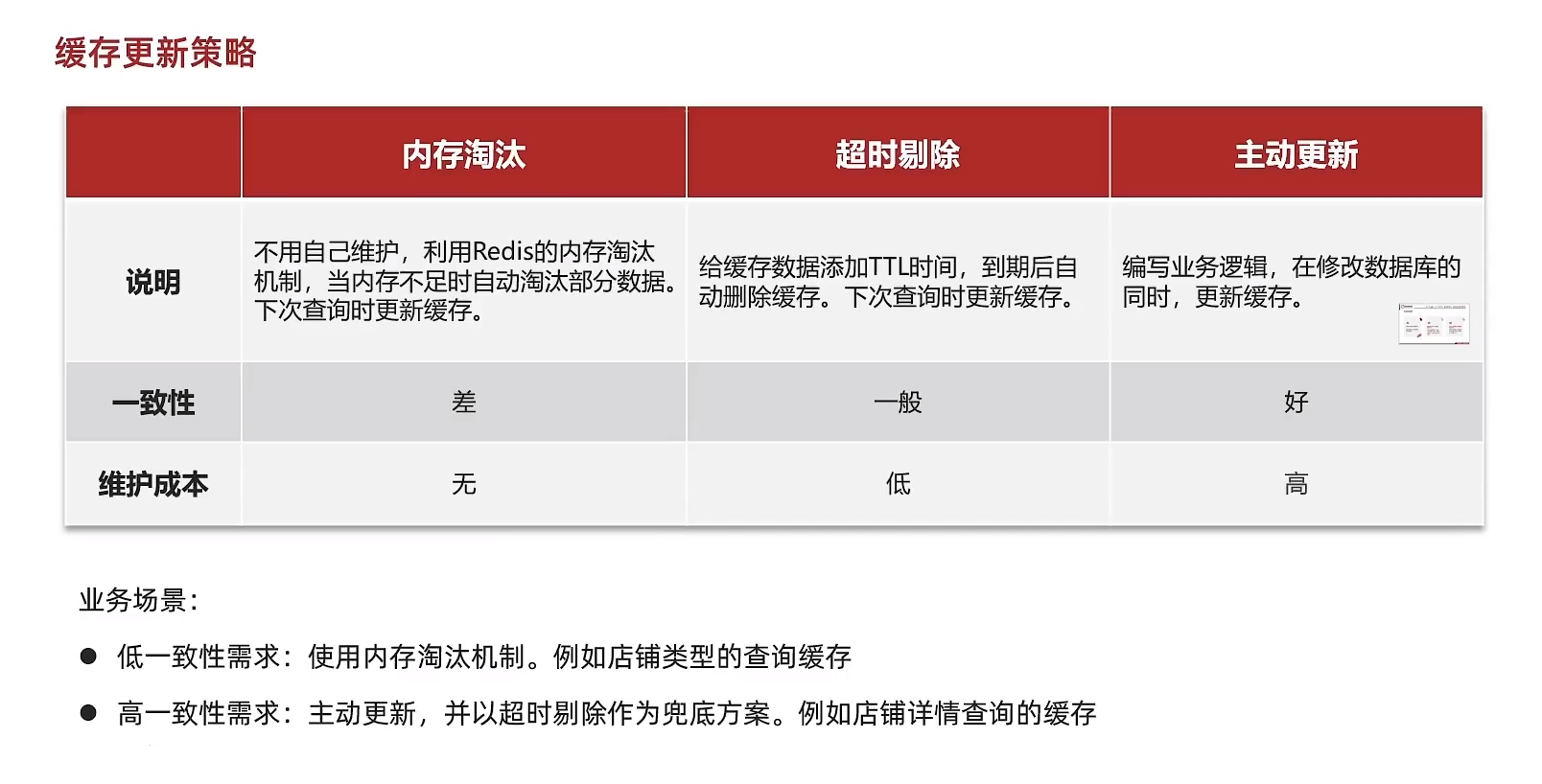
主动更新策略

Cache Adide Pattern

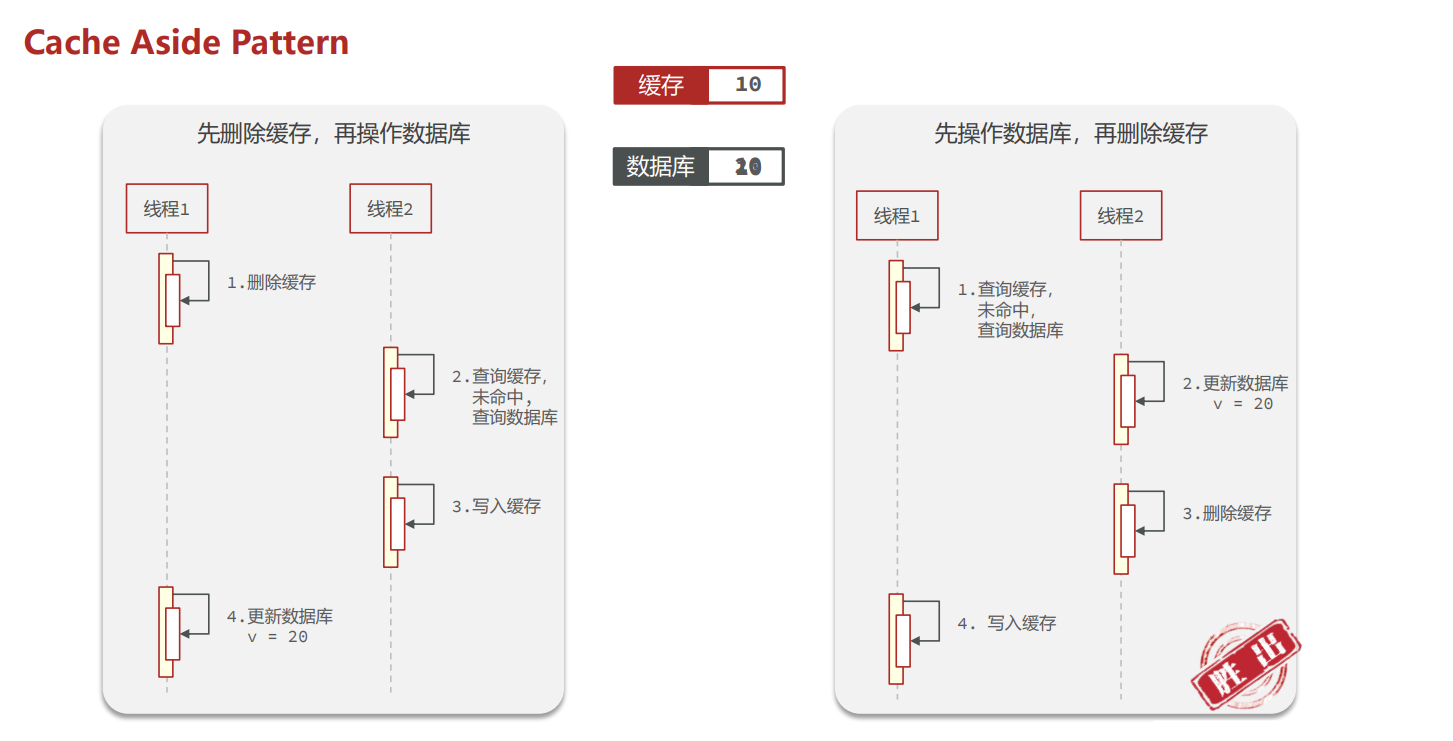
缓存更新策略最佳方案

缓存穿透
什么是缓存穿透
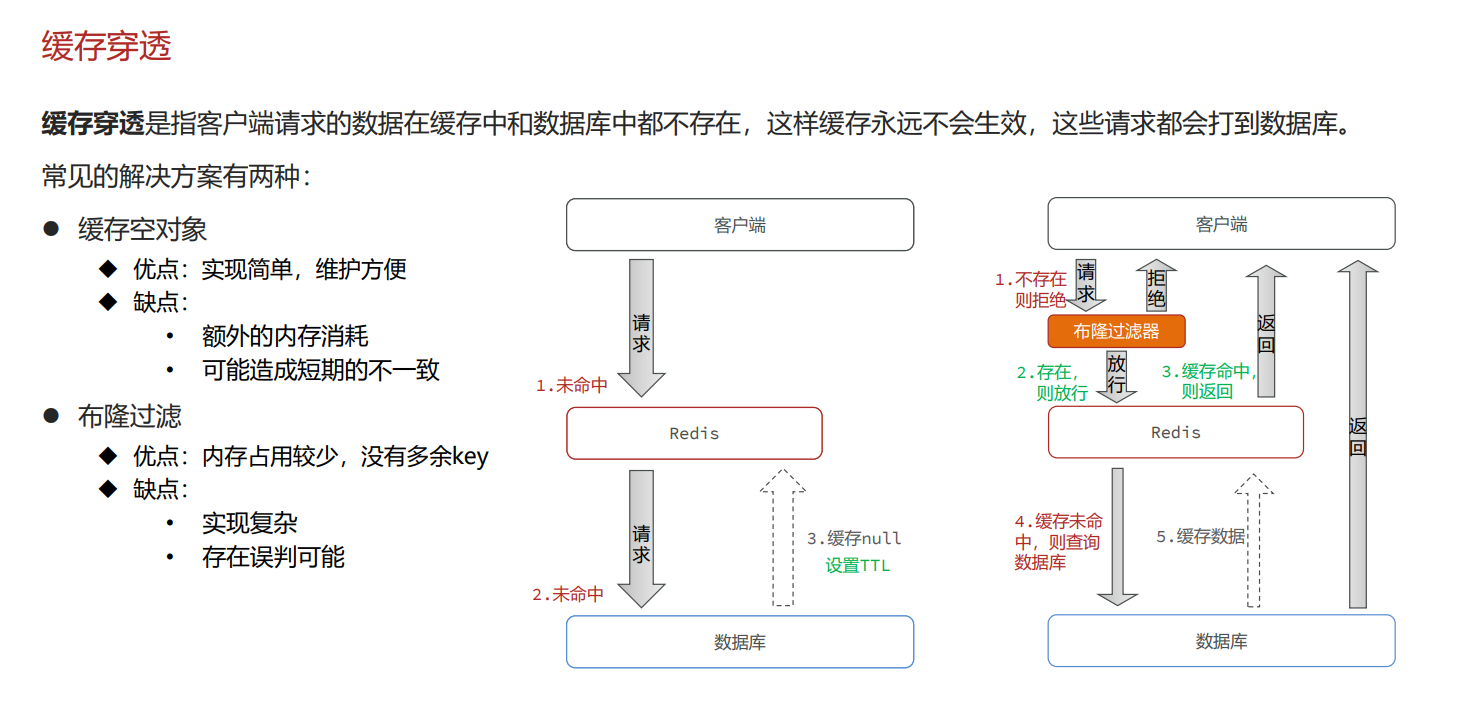
缓存空对象解决方案
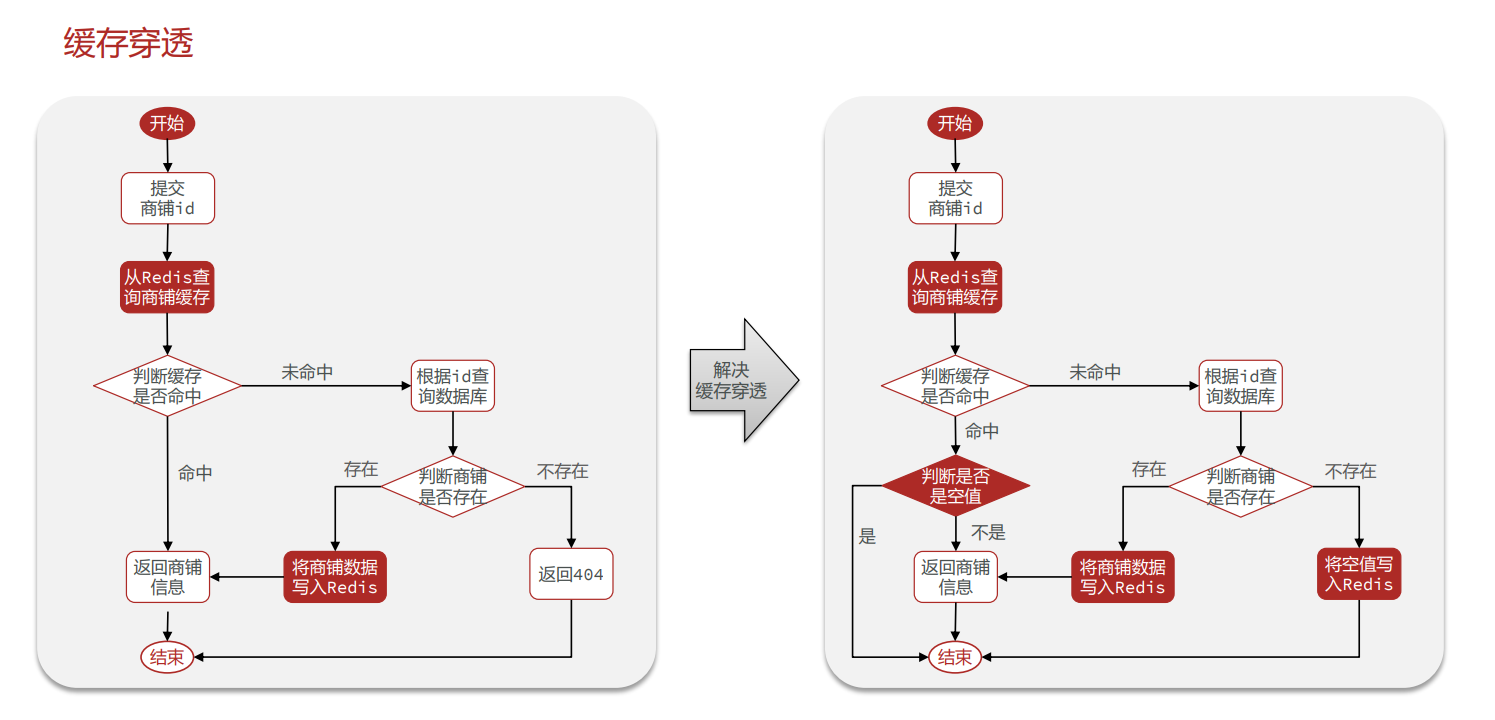
缓存穿透产生的原因是什么?
用户请求的数据在缓存中和数据库中都不存在,不断发起这样的请 求,给数据库带来巨大压力 缓存穿透的解决方案有哪些?
被动防御
- 缓存null值
- 布隆过滤
主动防御
增强id的复杂度,避免被猜测id规律
做好数据的基础格式校验
加强用户权限校验
做好热点参数的限流
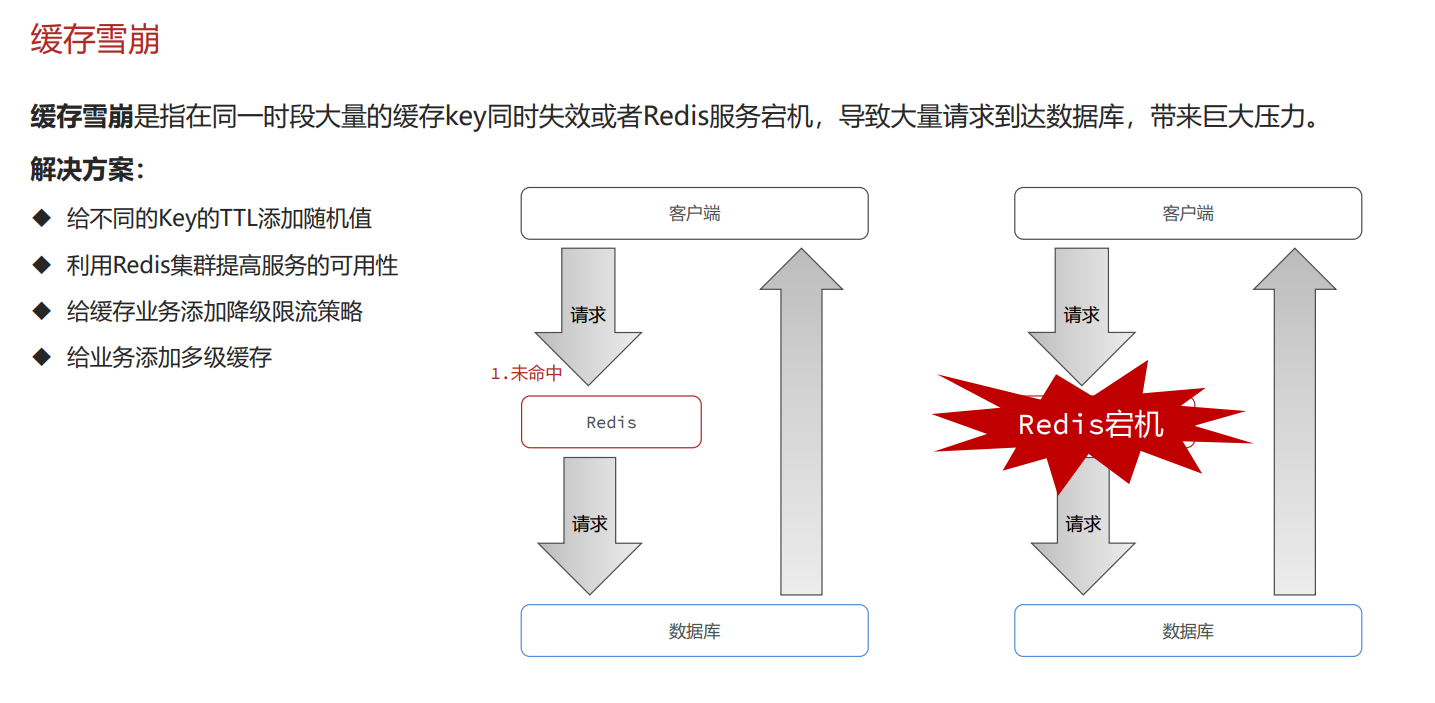
缓存雪崩
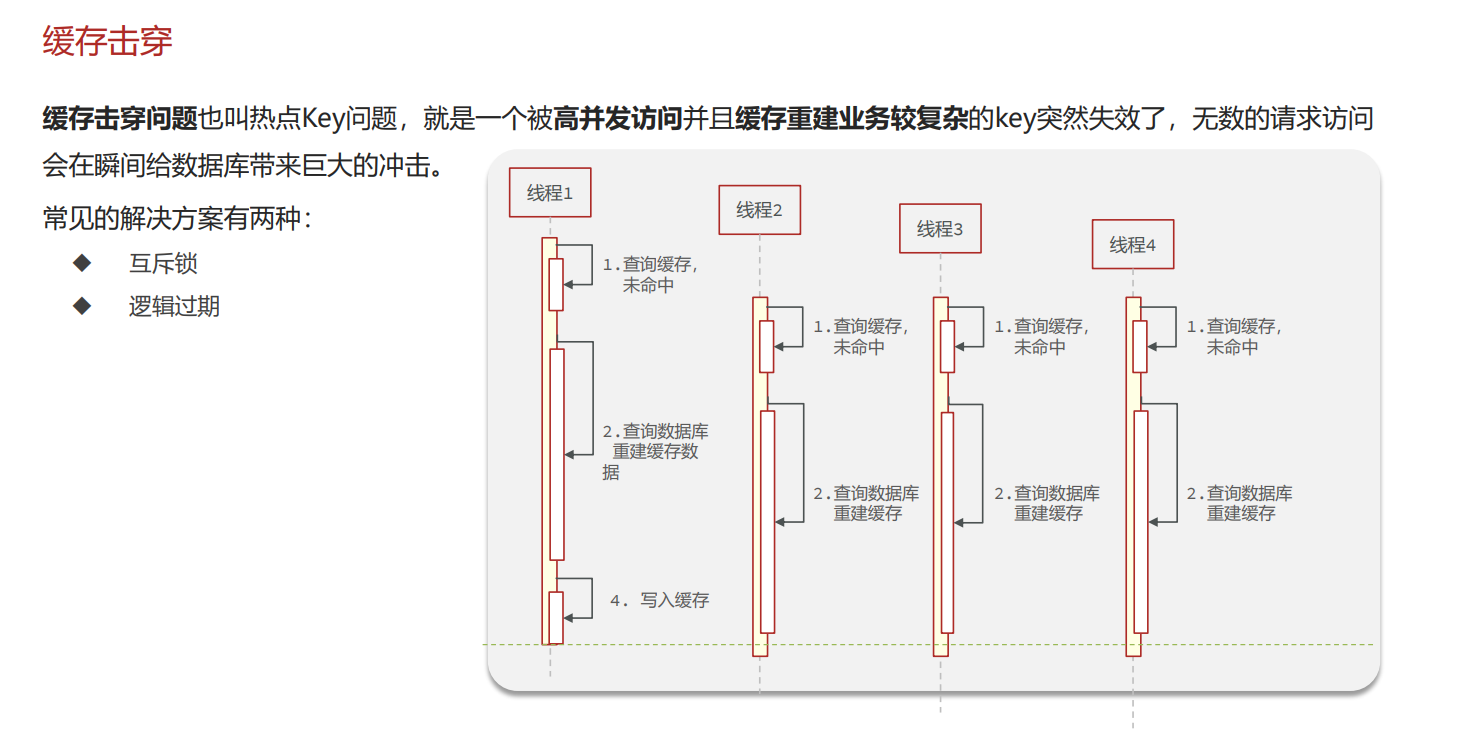
缓存击穿
什么是缓存击穿
缓存击穿解决方案
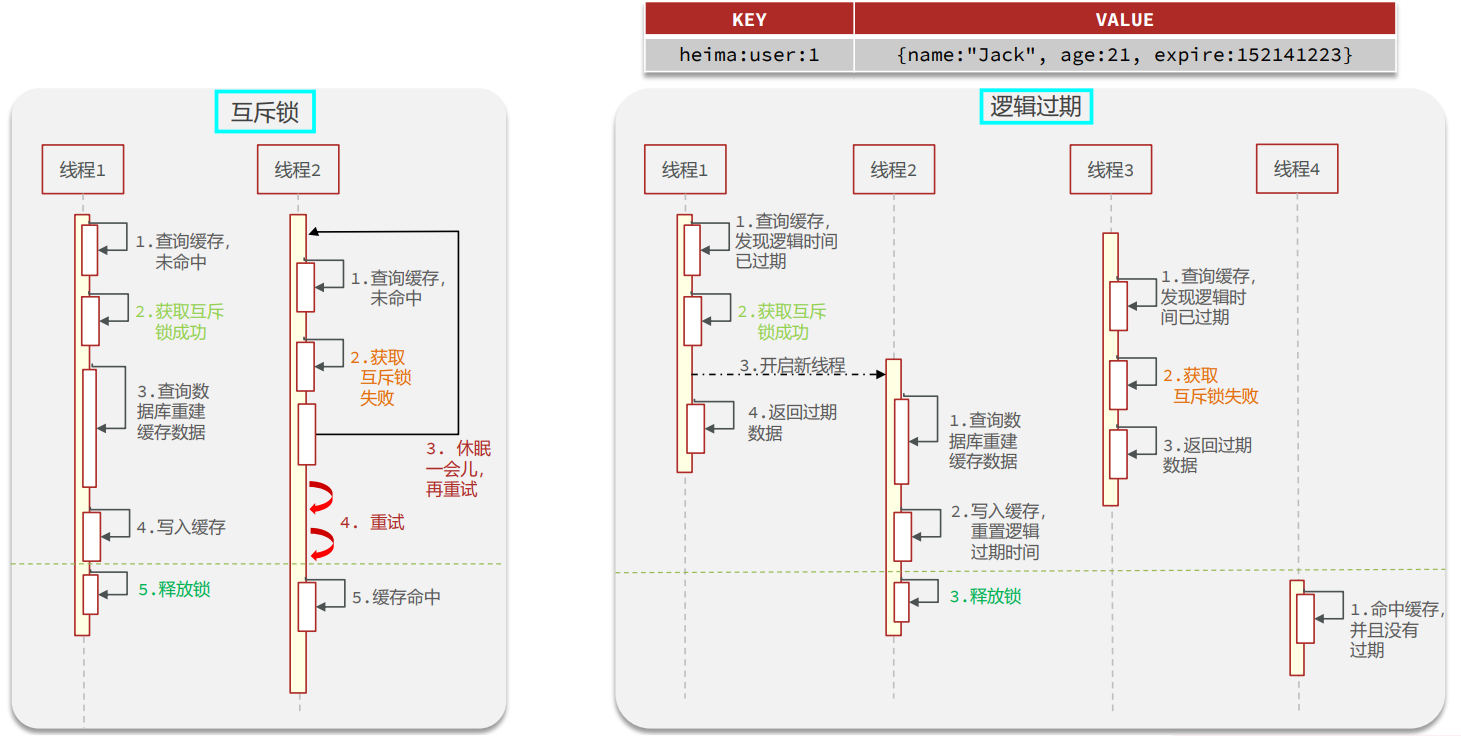
两种方案的优缺点

**一致还是性能,这是个值得思考的问题~ **
案例解决方案
缓存案例
|
缓存穿透 —缓存空对象
/** |
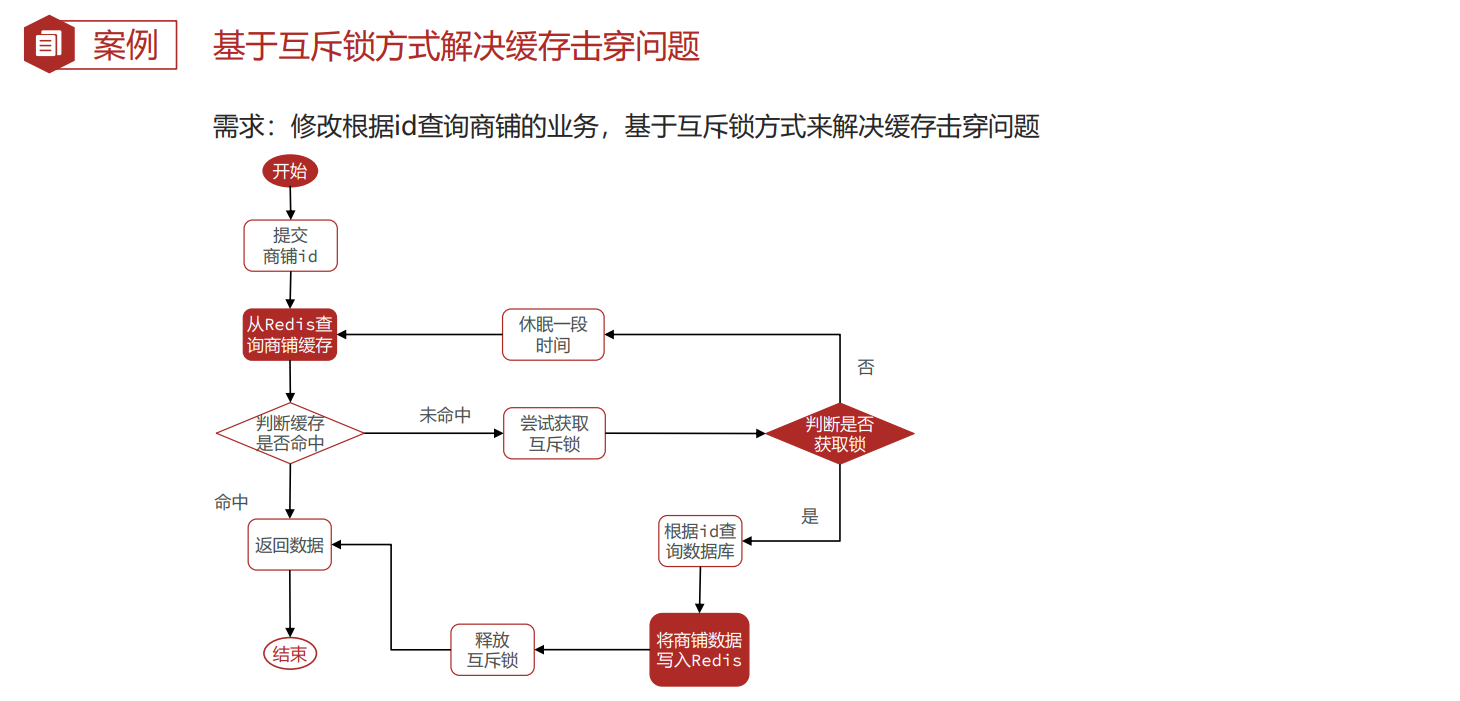
缓存击穿 —互斥锁方案
/** |
互斥锁的简单构建
//获取互斥锁 |
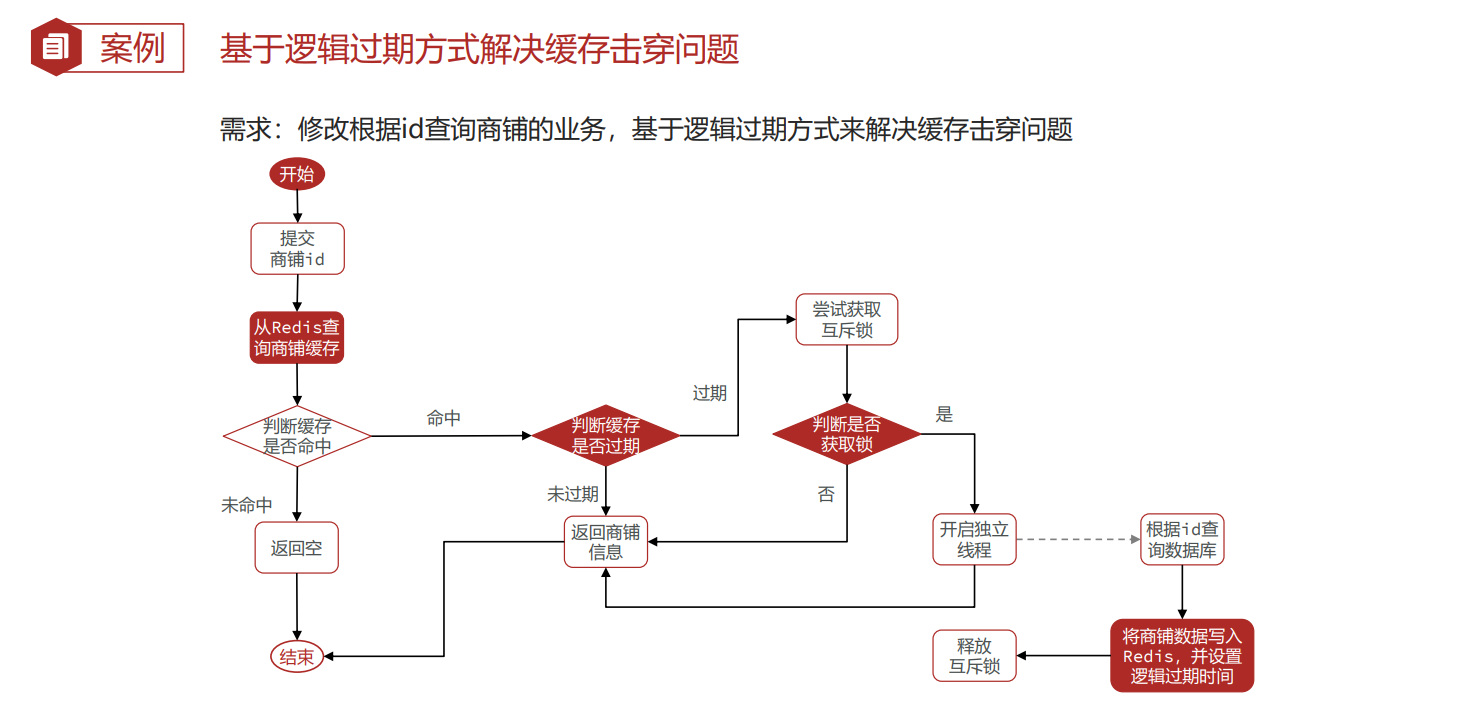
缓存击穿 —逻辑过期方案
数据的变动
import lombok.Data; |
缓存重建方法
//缓存重建 |
业务逻辑
/** |
缓存工具封装
**U基于StringRedisTemplate封装一个缓存工具类,满足下列需求: **
✓ 方法1:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间
✓ 方法2:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓存 击穿问题
✓ 方法3:根据指定的key查询缓存,并反序列化为指定类型,利用缓存空值的方式解决缓存穿透问题
✓ 方法4:根据指定的key查询缓存,并反序列化为指定类型,需要利用逻辑过期解决缓存击穿问题
package com.ayaka.utils; |
Redis解决 [生成全局ID方案]
解决方案:
package com.ayaka.utils; |
测试代码
package com.ayaka; |
Redis解决 [秒杀] [秒杀优惠卷]
秒杀卷库表设计
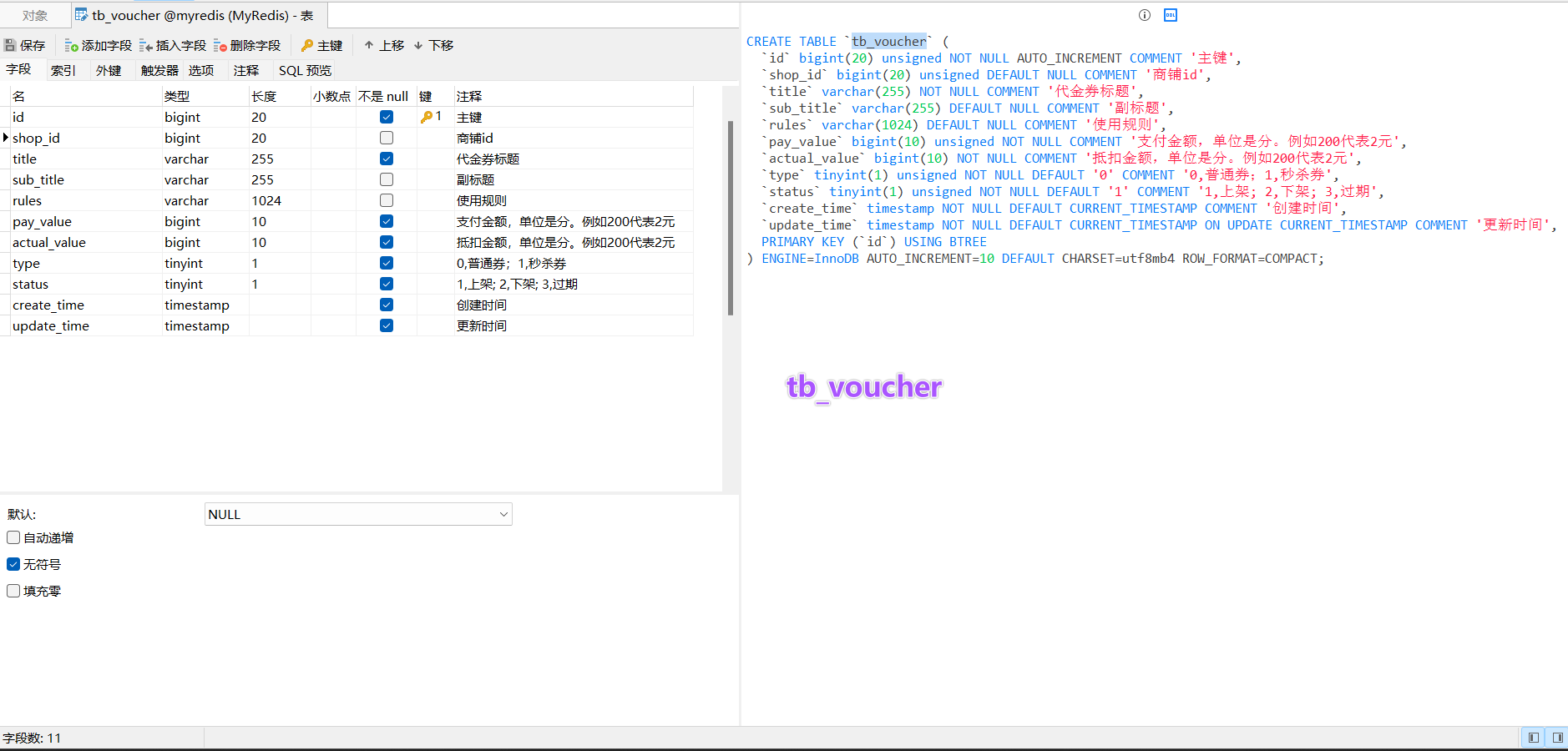
tb_voucher 优惠卷的基本信息
tb_seckill_voucher 特价/秒杀 优惠卷的拓展信息
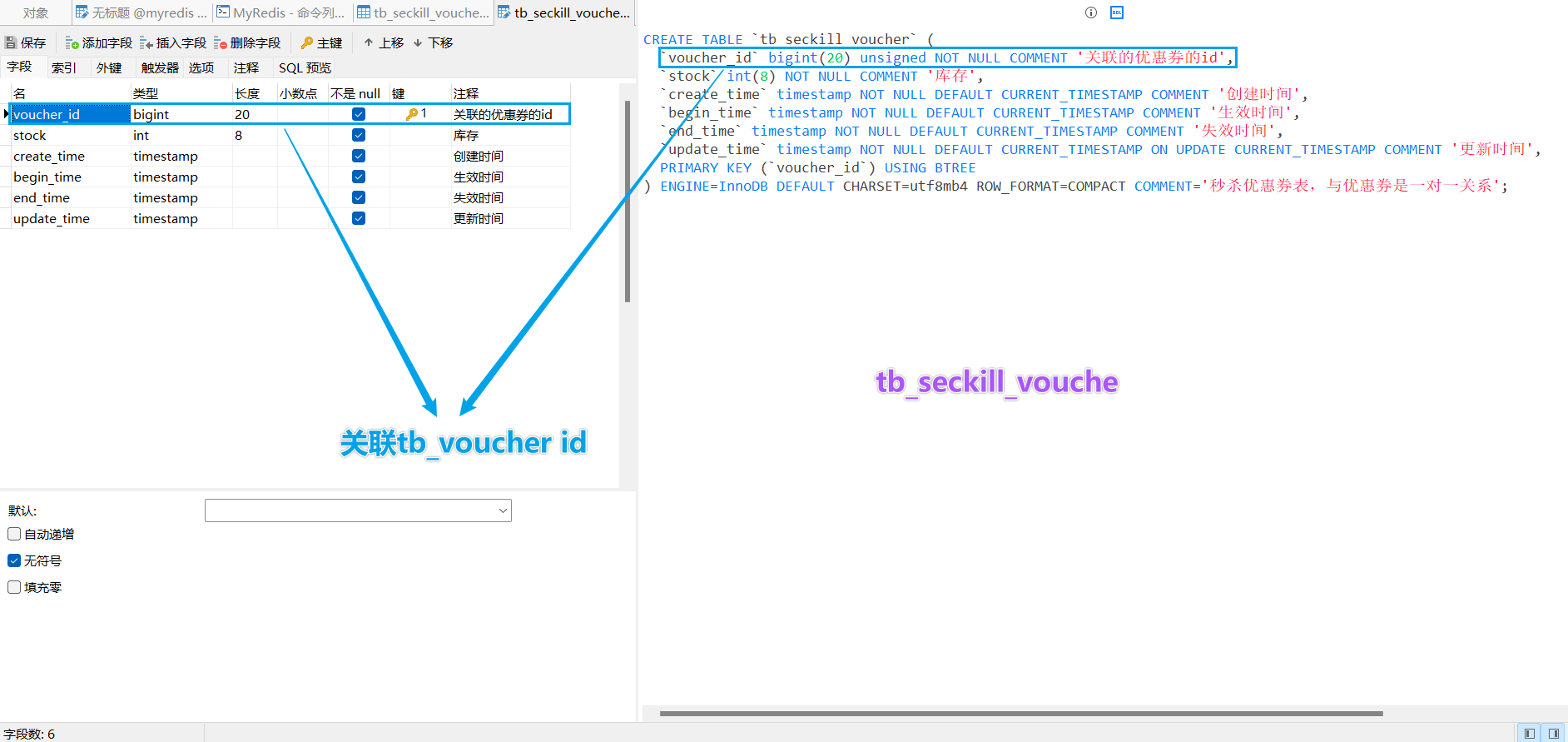
SQL
# tb_voucher |
添加秒杀卷
VoucherController
/** |
VoucherServiceImpl
//也就是说 秒杀卷 也包含的普通卷的创建 |
也就是说 秒杀卷 也包含的普通卷的创建
POST http://localhost:8081/voucher/seckill |
秒杀卷下单
库表设计:tb_voucher_order
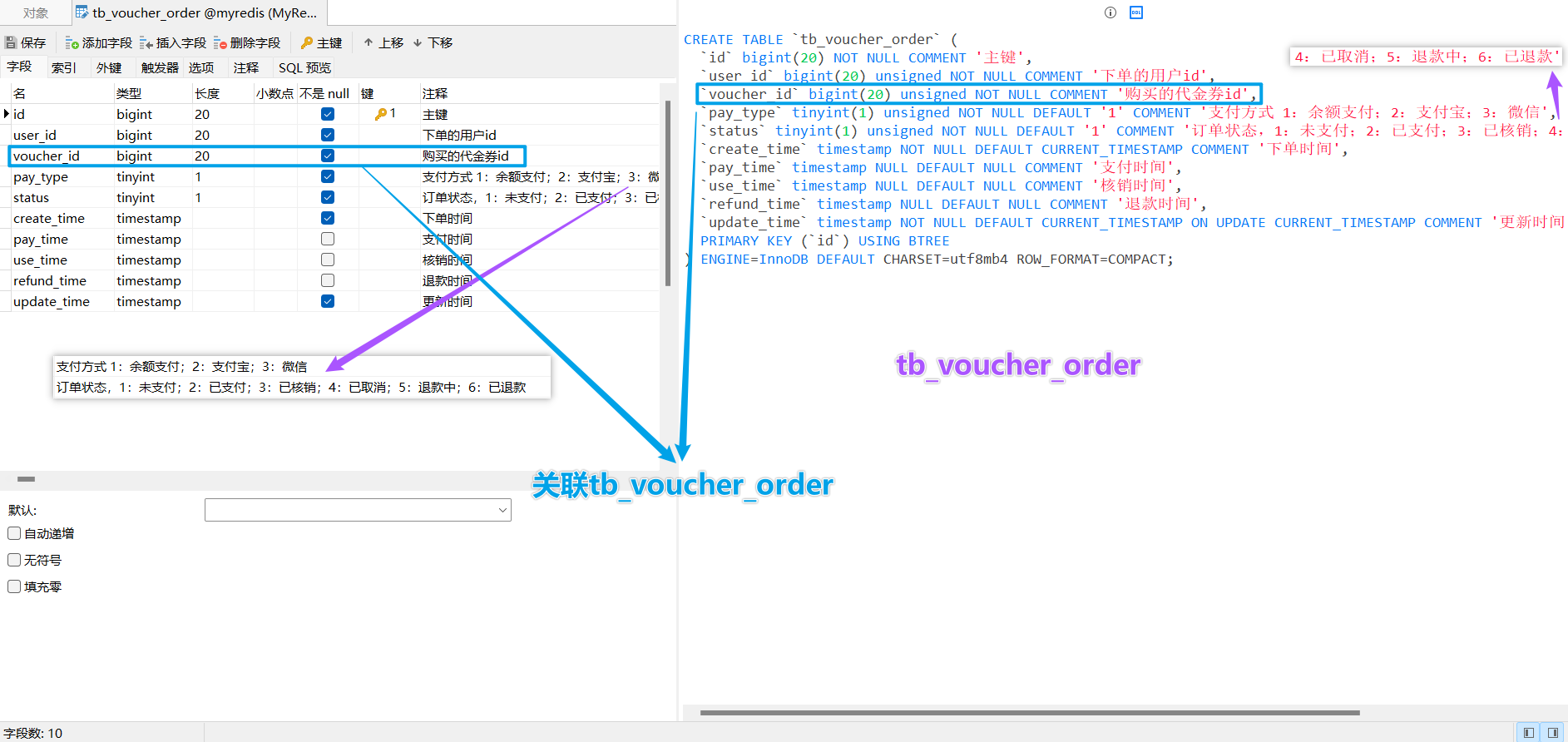
# tb_vouche_order |
实体类:Voucher
|
下单流程:
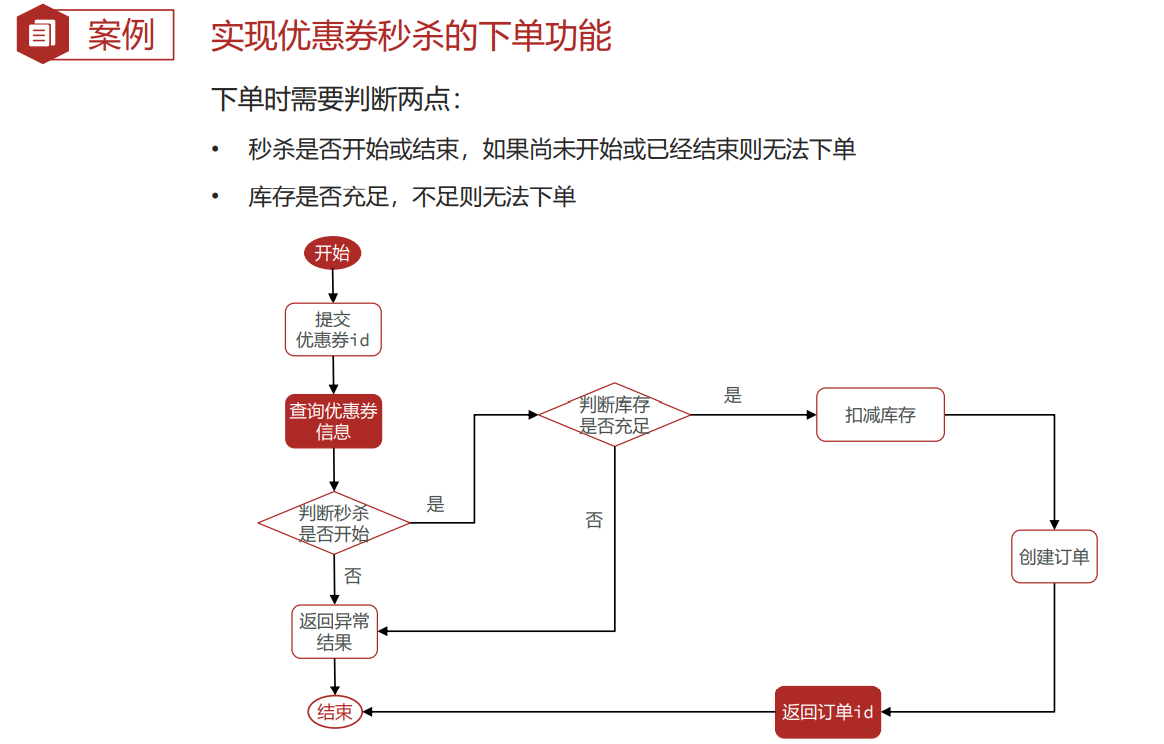
业务代码:
package com.ayaka.service.impl; |
存在问题:
- 【超卖问题】 并发情况下,会出现线程安全问题 【超卖问题】
- 【一人一单】 一人可以下多单,应该是一人只能抢一个秒杀卷 【一人一单】
问题–超卖问题
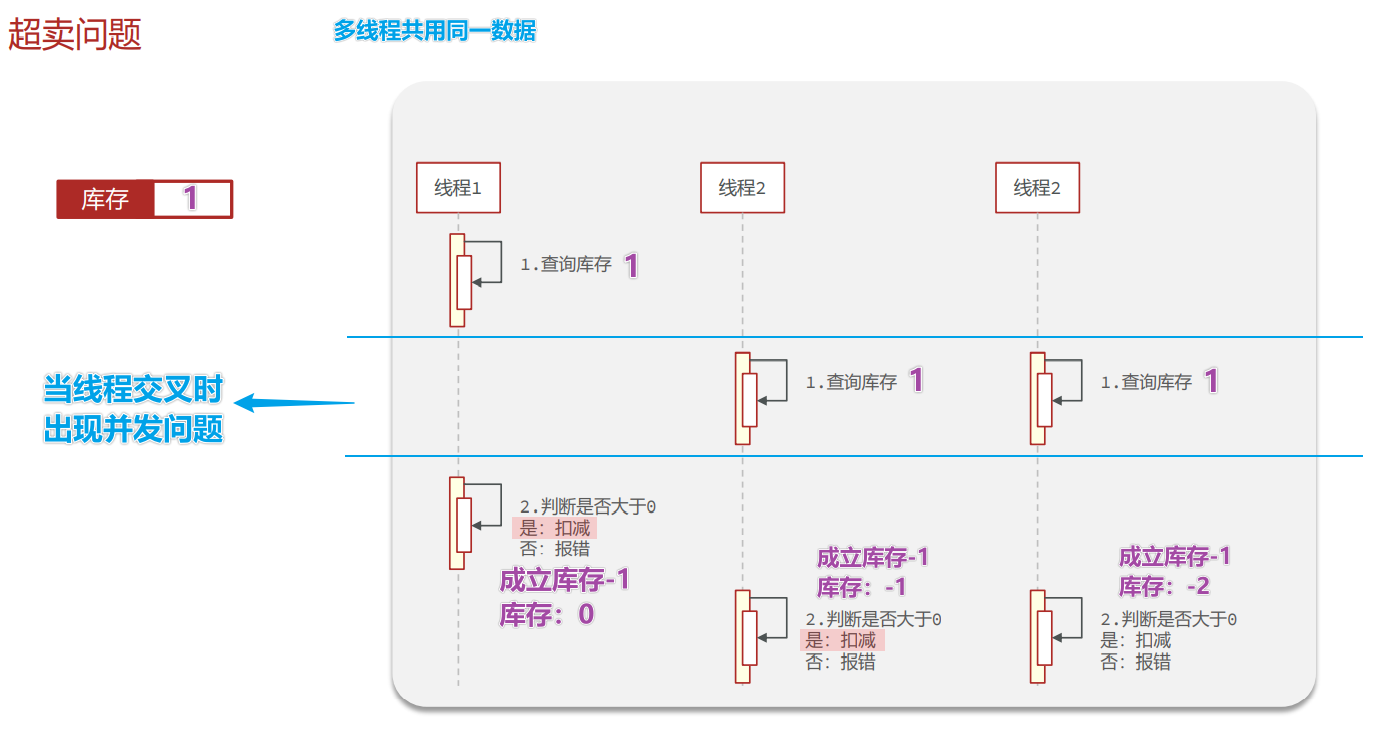
解决方案 : 加锁
锁的选择:
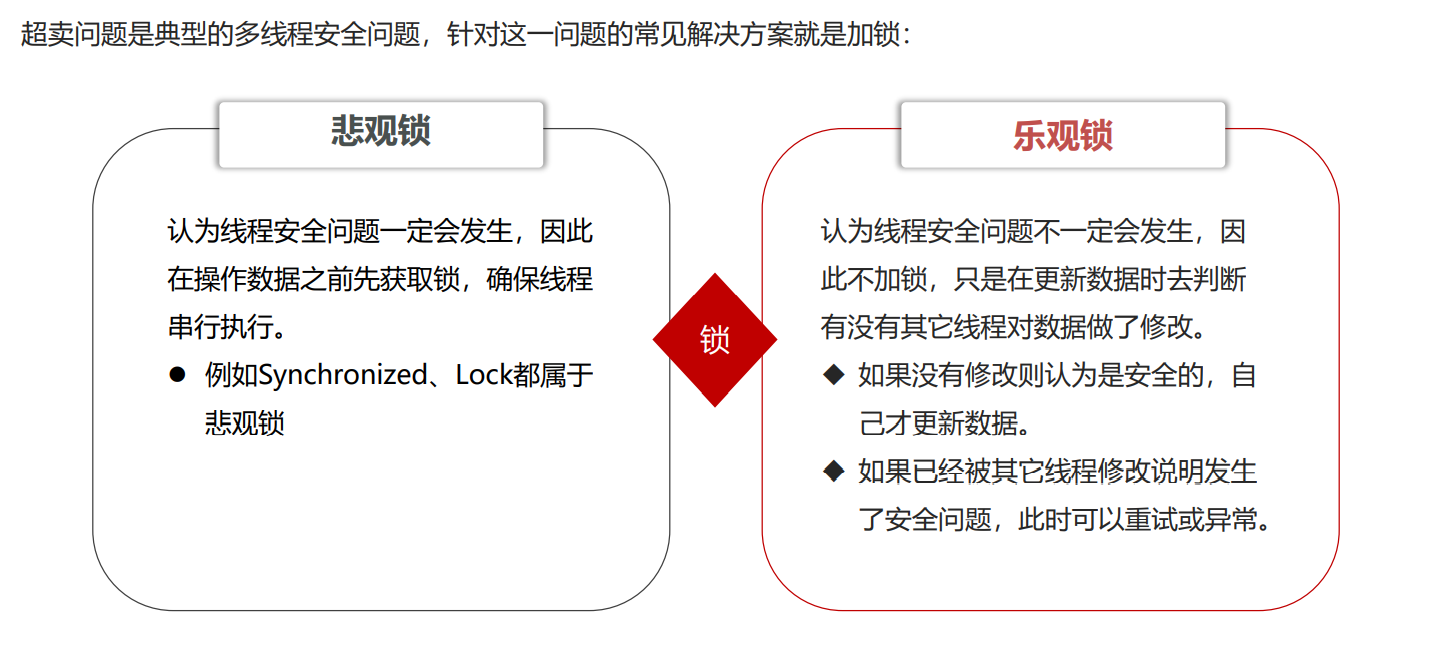
乐观锁:
版本号法
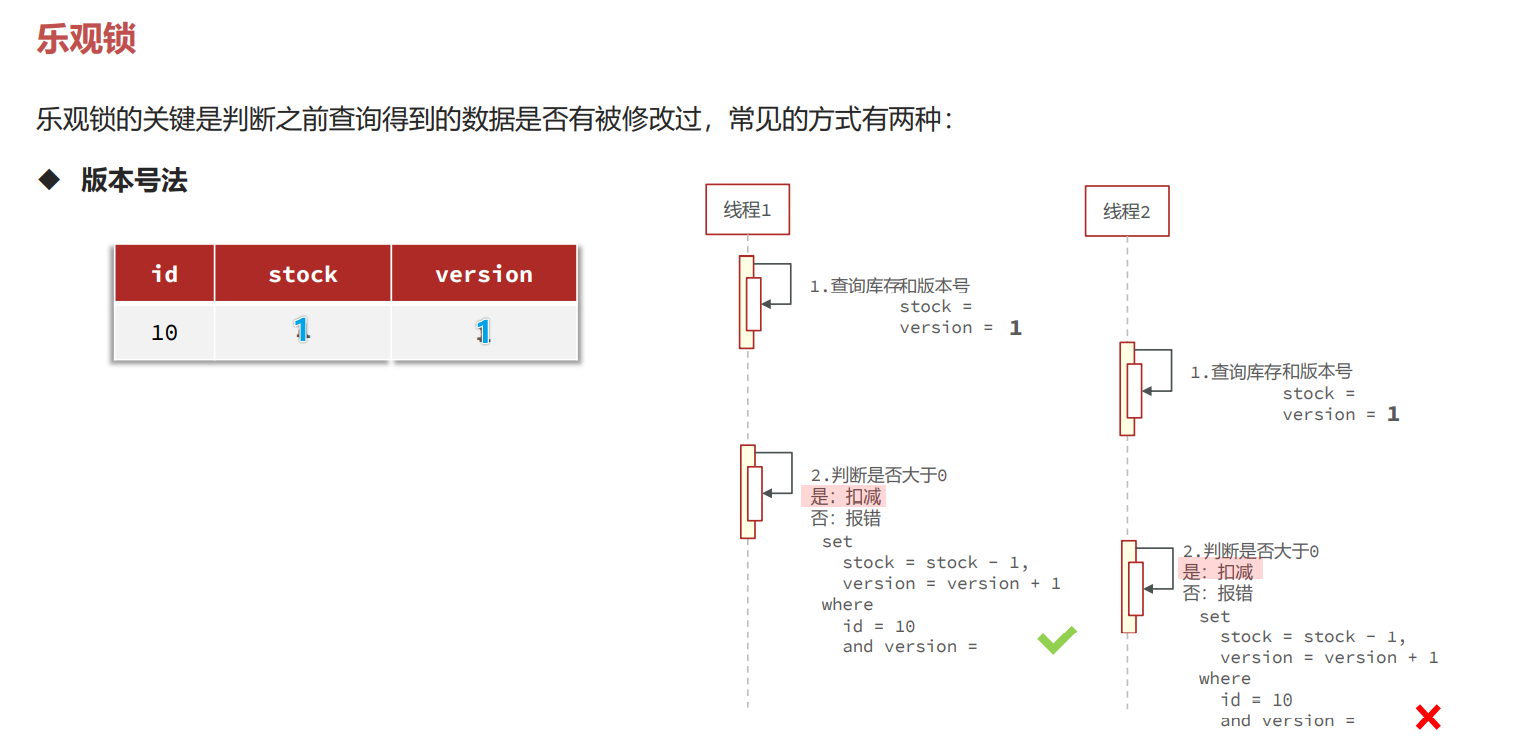
CAS法
超卖这样的线程安全问题,解决方案有哪些?
悲观锁:添加同步锁,让线程串行执行
• 优点:简单粗暴
• 缺点:性能一般
乐观锁:不加锁,在更新时判断是否有其它线程在修改
• 优点:性能好
• 缺点:存在成功率低的问题
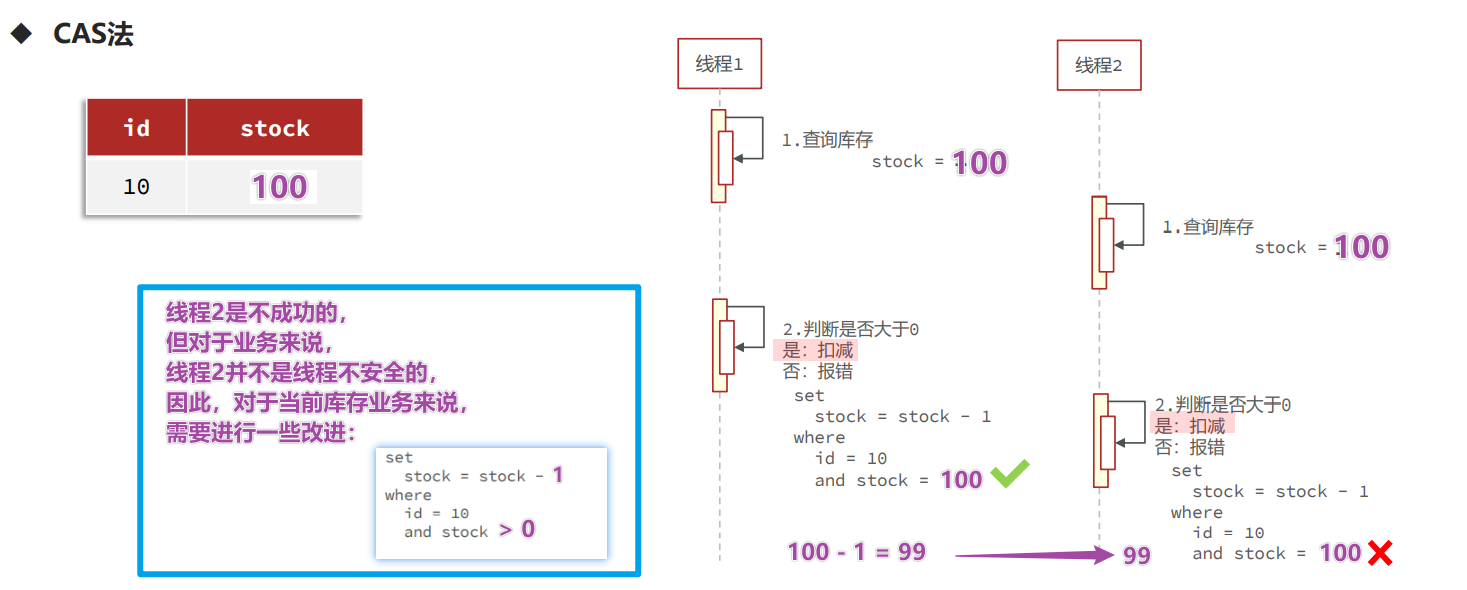
解决问题:
package com.ayaka.service.impl; |
问题–一人一单
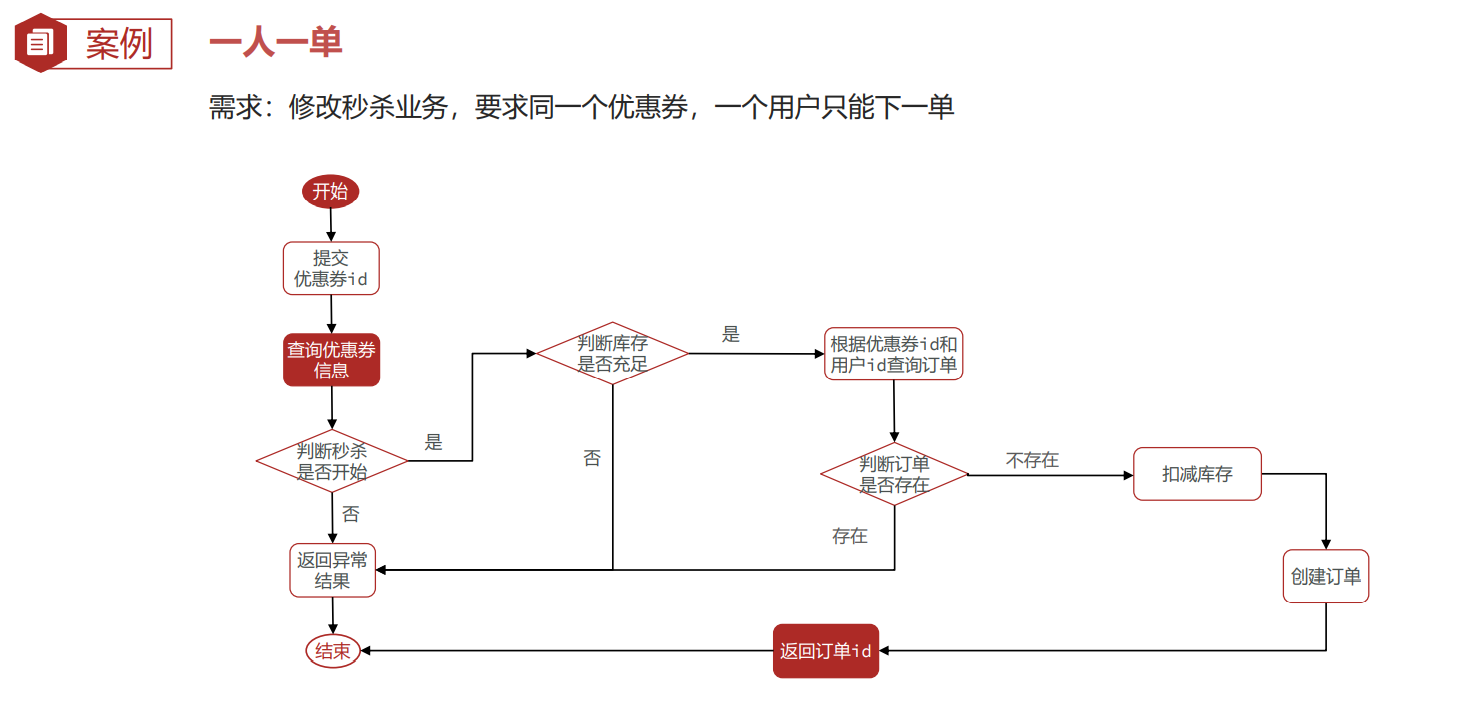
重点!!!!!!!
/** |
业务的实现
|
暴露代理对象
<dependency> |
//暴露动态代理 |
以上依然存在问题!
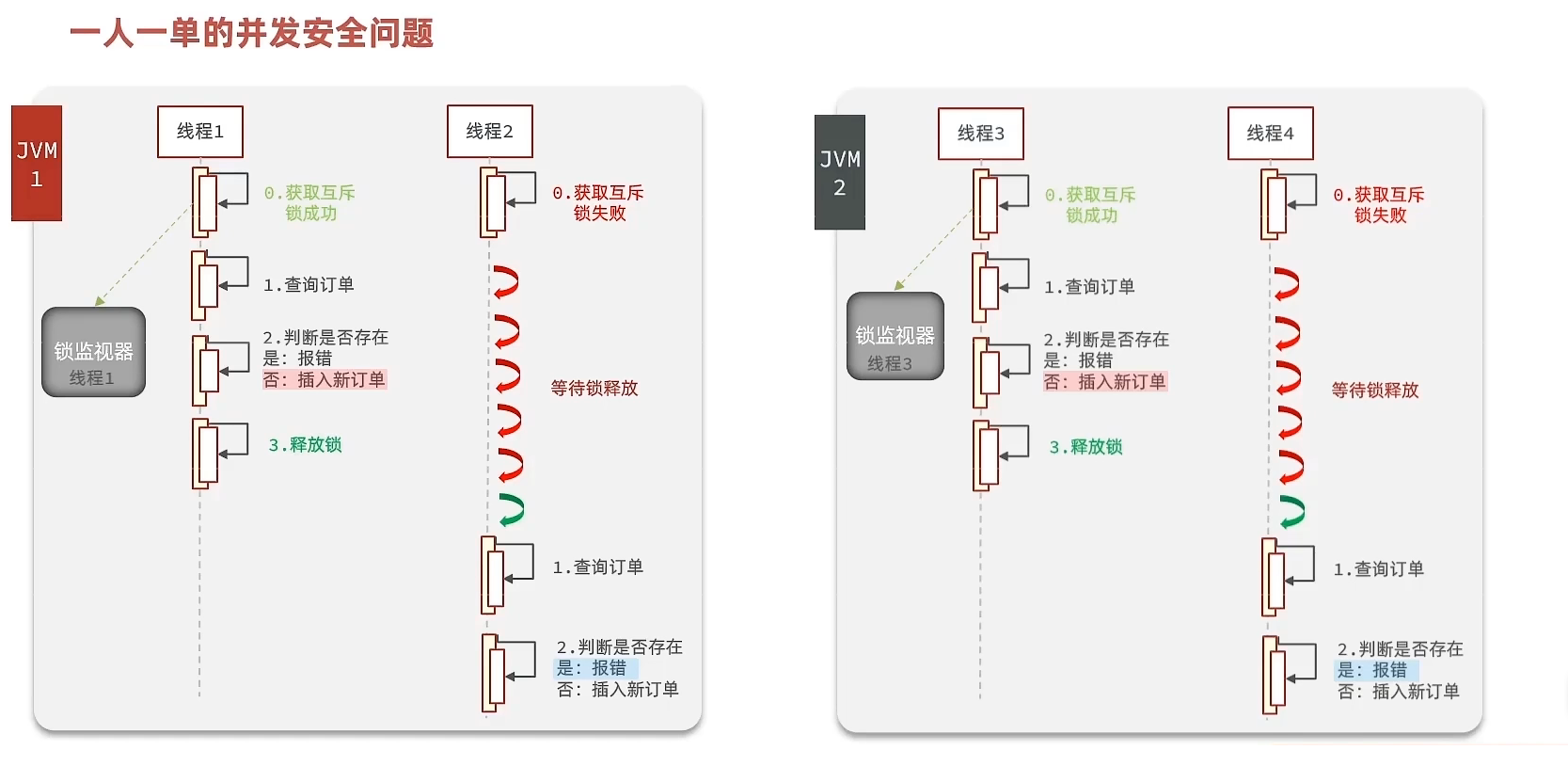
在集群 或 分布式系统下 , 每个JVM的锁监视器是独立的,就会出现并发安全问题
解决方案:使用 分布式锁
下面👇
Redis解决 [分布式锁]
分布式锁
什么是分布式锁
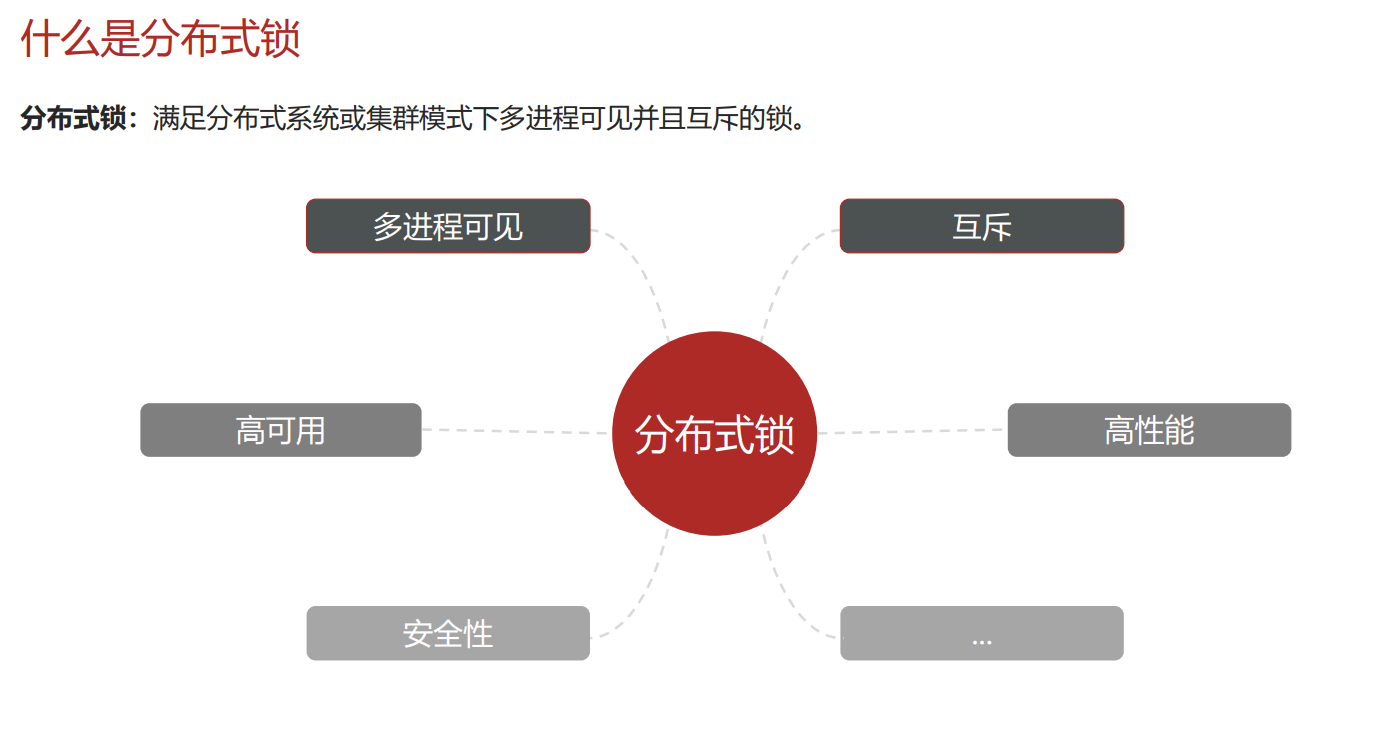
分布式锁的实现
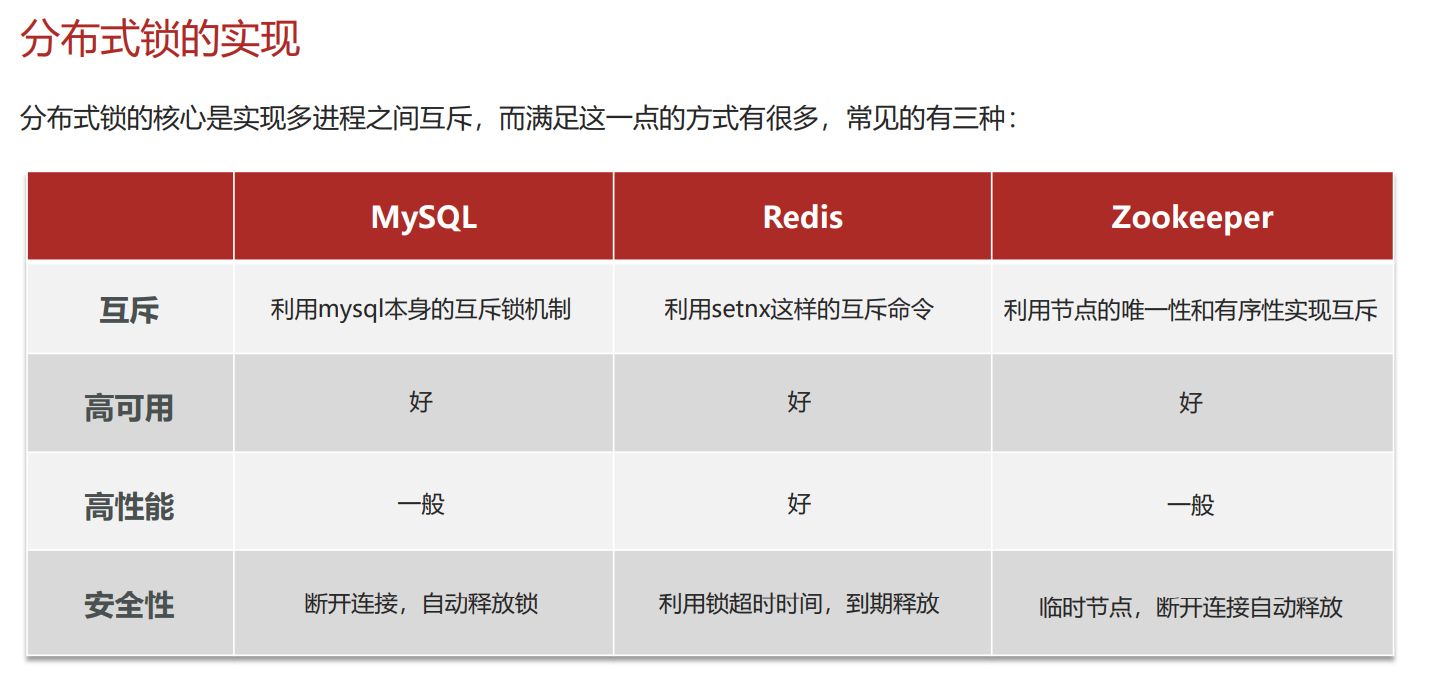
基于Redis的分布式锁
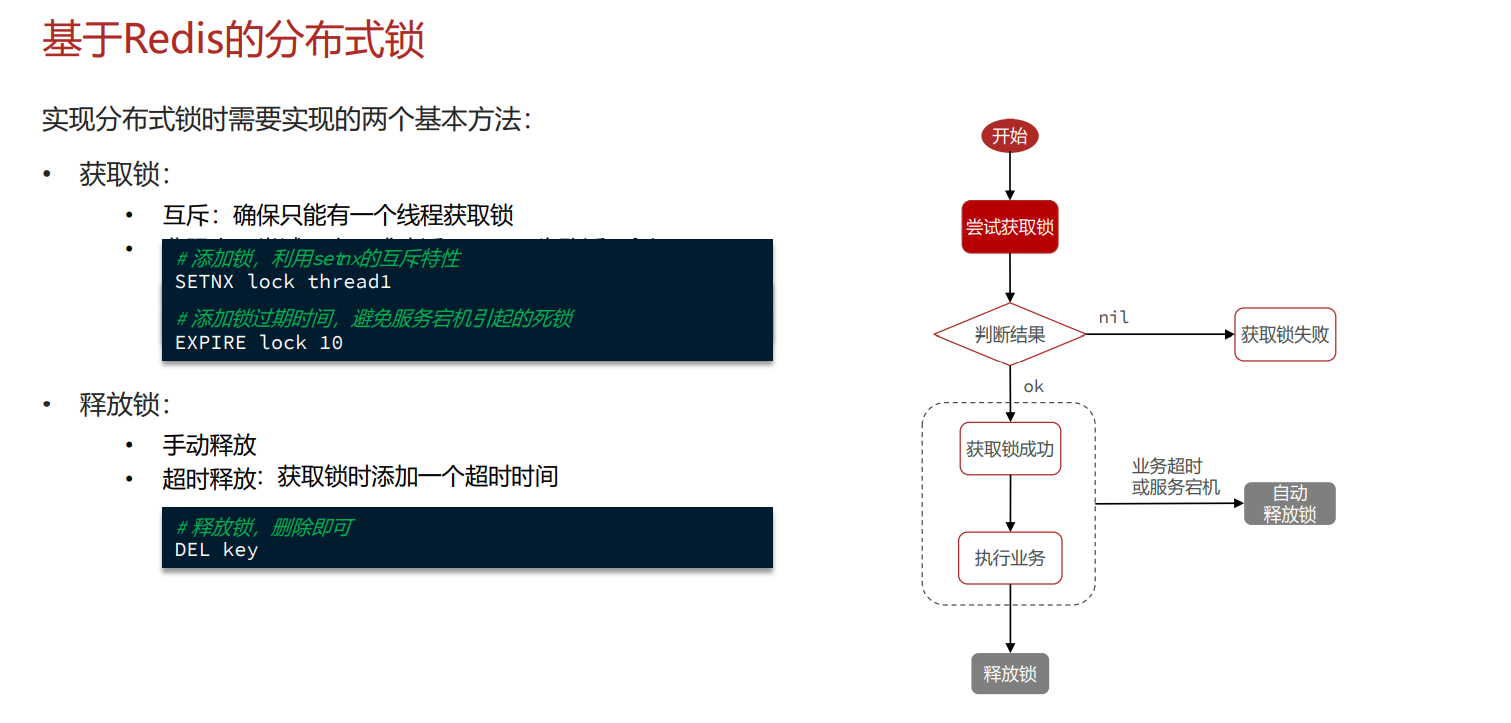
一个简单的实现:
/** |
impl
package com.ayaka.utils; |
业务:
package com.ayaka.service.impl; |
存在的问题:误删问题
上面的简单实现
在正常情况下:
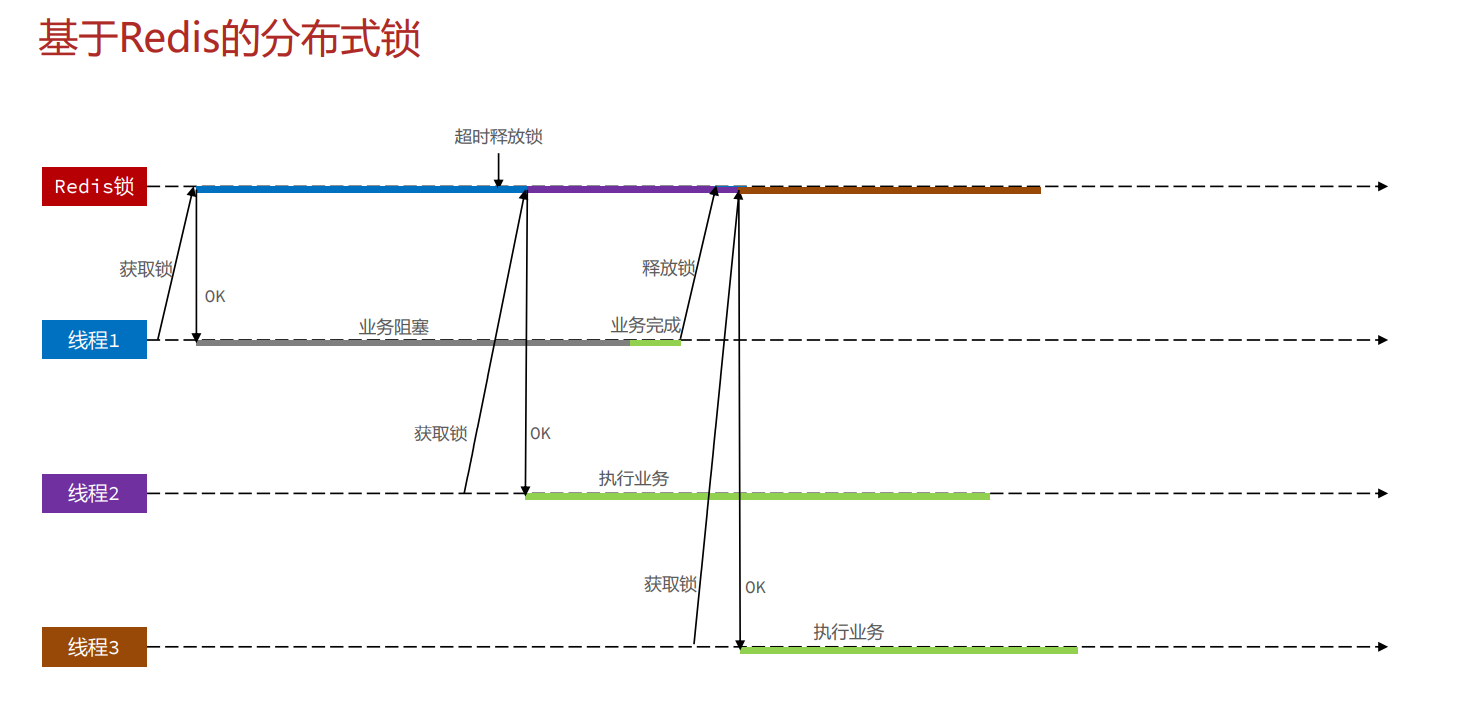
极端情况下:
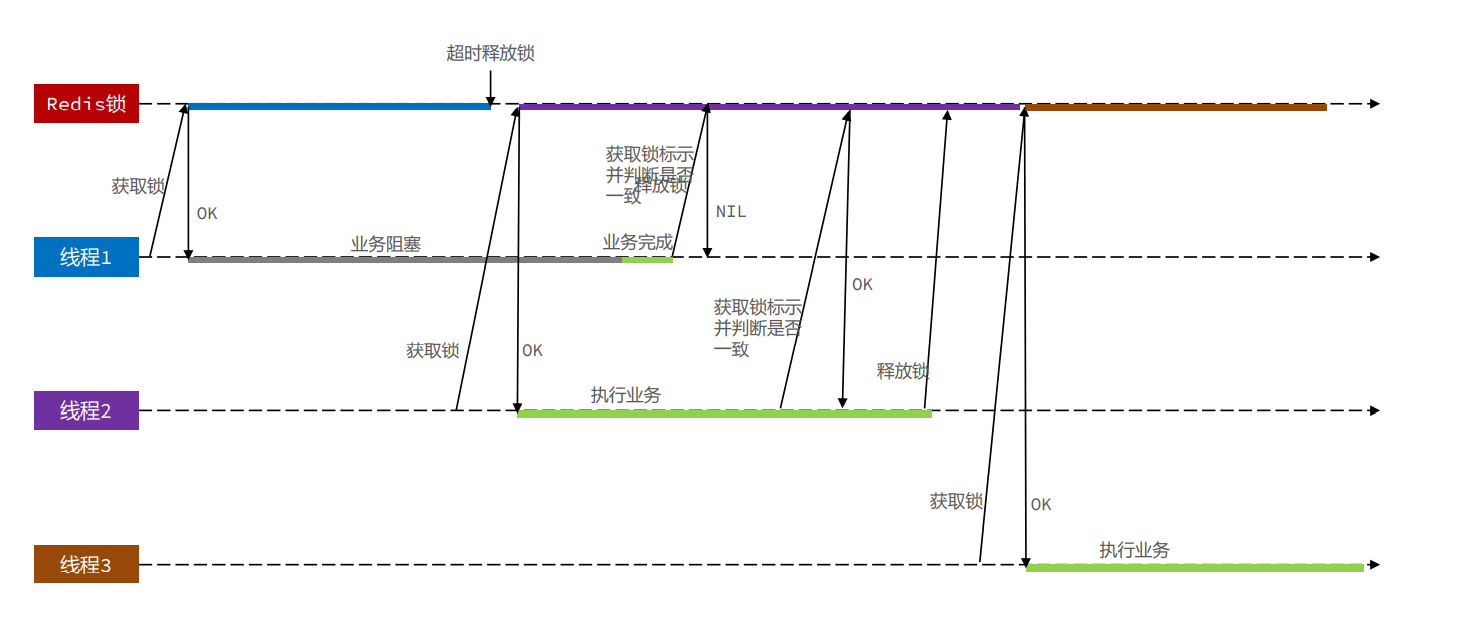
解决方案:
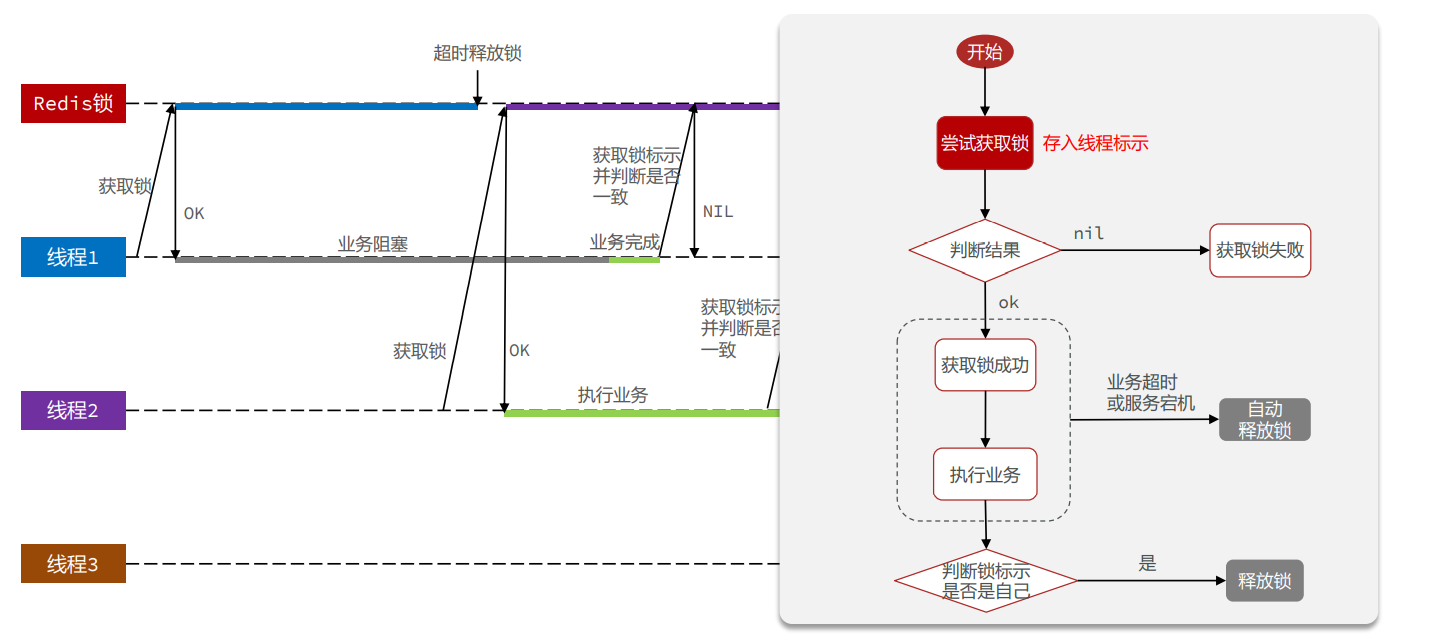
对 上面代码优化:
impl
package com.ayaka.utils; |
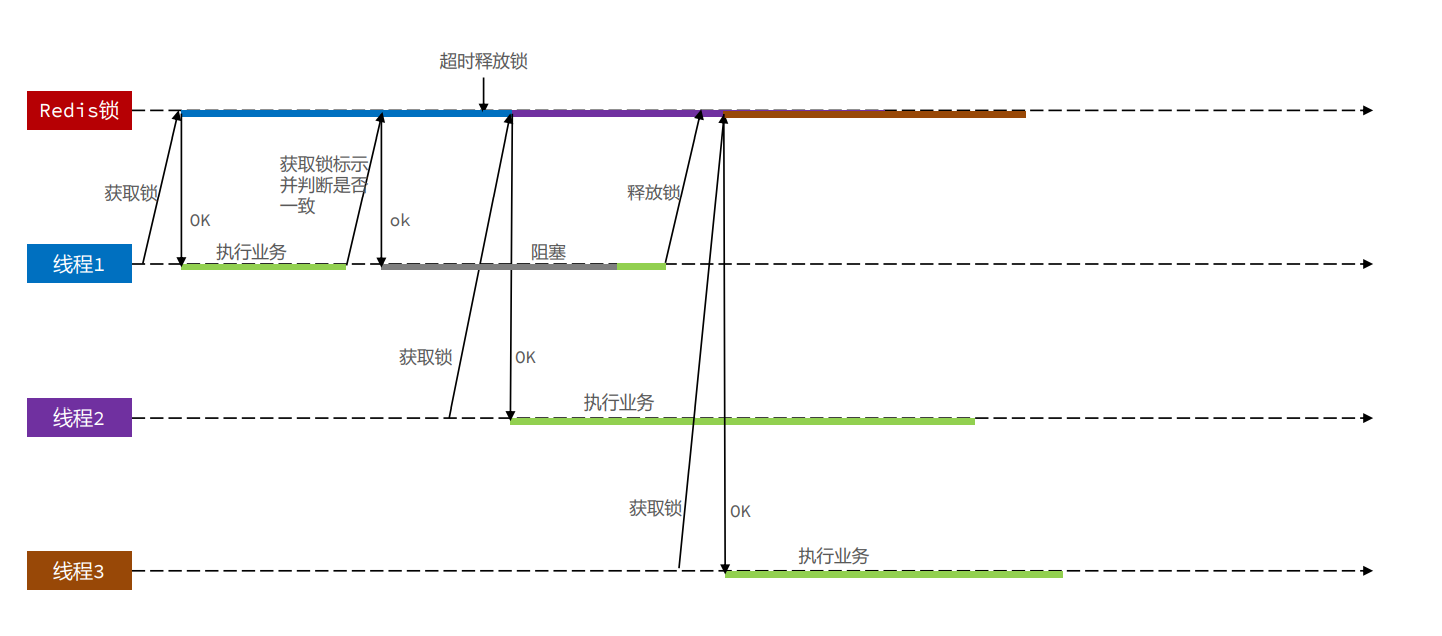
依然存在问题:原子性
删除锁时 判断锁的标识 和 释放锁 并发问题
极端情况下:
判断锁的标识 后 发生阻塞,超时释放了锁,此时其它线程获取锁,那么这个线程释放的锁 就是 其他线程的锁了
改进方案:
- Redis的事务功能:麻烦不用
- Redis的Lua脚本
Redis的Lua脚本
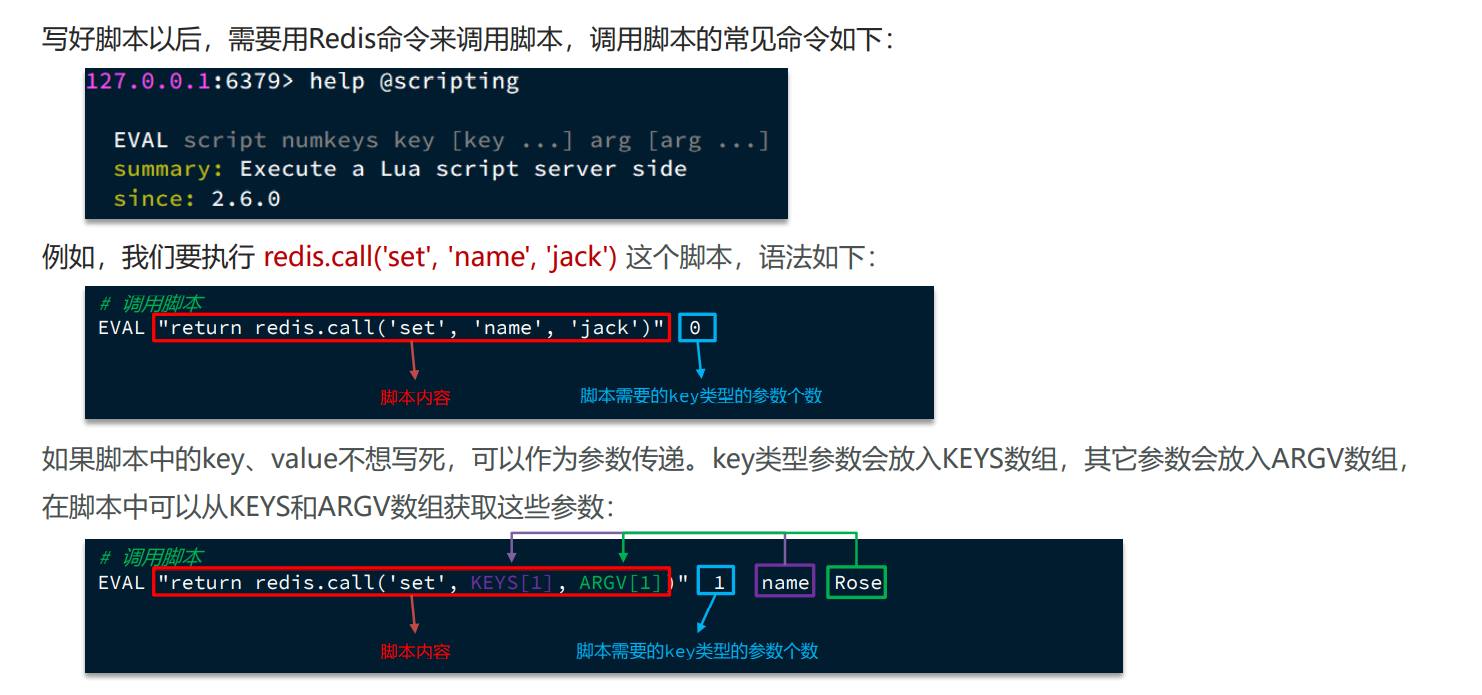
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。Lua是一种 编程语言,它的基本语法大家可以参考网站:https://www.runoob.com/lua/lua-tutorial.html 这里重点介绍Redis提供的调用函数,语法如下:
redis.call('命令名称', 'key', '其它参数', ...)例如,我们要执行set name jack,则脚本是这样:
redis.call('set', 'name', 'jack')例如,我们要先执行set name Rose,再执行get name,则脚本如下:
redis.call('set', 'name', 'jack')
# 再执行 get name
local name = redis.call('get', 'name')
# 返回
return name
Redis的Lua脚本的执行
释放锁的业务流程是这样的:
获取锁中的线程标示
判断是否与指定的标示(当前线程标示)一致
如果一致则释放锁(删除)
如果不一致则什么都不做 如果用Lua脚本来表示则是这样的:
-- 这里的 KEYS[1] 就是锁的key,这里的ARGV[1] 就是当前线程标示
-- 获取锁中的标示,判断是否与当前线程标示一致
if (redis.call('GET', KEYS[1]) == ARGV[1]) then
-- 一致,则删除锁
return redis.call('DEL', KEYS[1])
end
-- 不一致,则直接返回
return 0
对之前的impl进行优化:
resources/unlock.lua
-- 这里的 KEYS[1] 就是锁的key,这里的ARGV[1] 就是当前线程标示 |
impl
package com.ayaka.utils; |
到此 实现了一个较为完善的 基于Redis的分布式锁
但是…….在某些场景下 依然需要优化…….
基于Redis的分布式锁优化
还有些问题可以进一步优化:

这些实现起来比较繁琐
可以使用开源框架去解决:
**使用 Redisson **👇
Redisson解决Redis分布式锁
Redisson介绍
Redisson Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。
它不仅提供了一系列的分布 式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
官网地址: https://redisson.org
GitHub地址: https://github.com/redisson/redisson
简单的使用
package com.ayaka.config; |
业务改造
package com.ayaka.service.impl; |
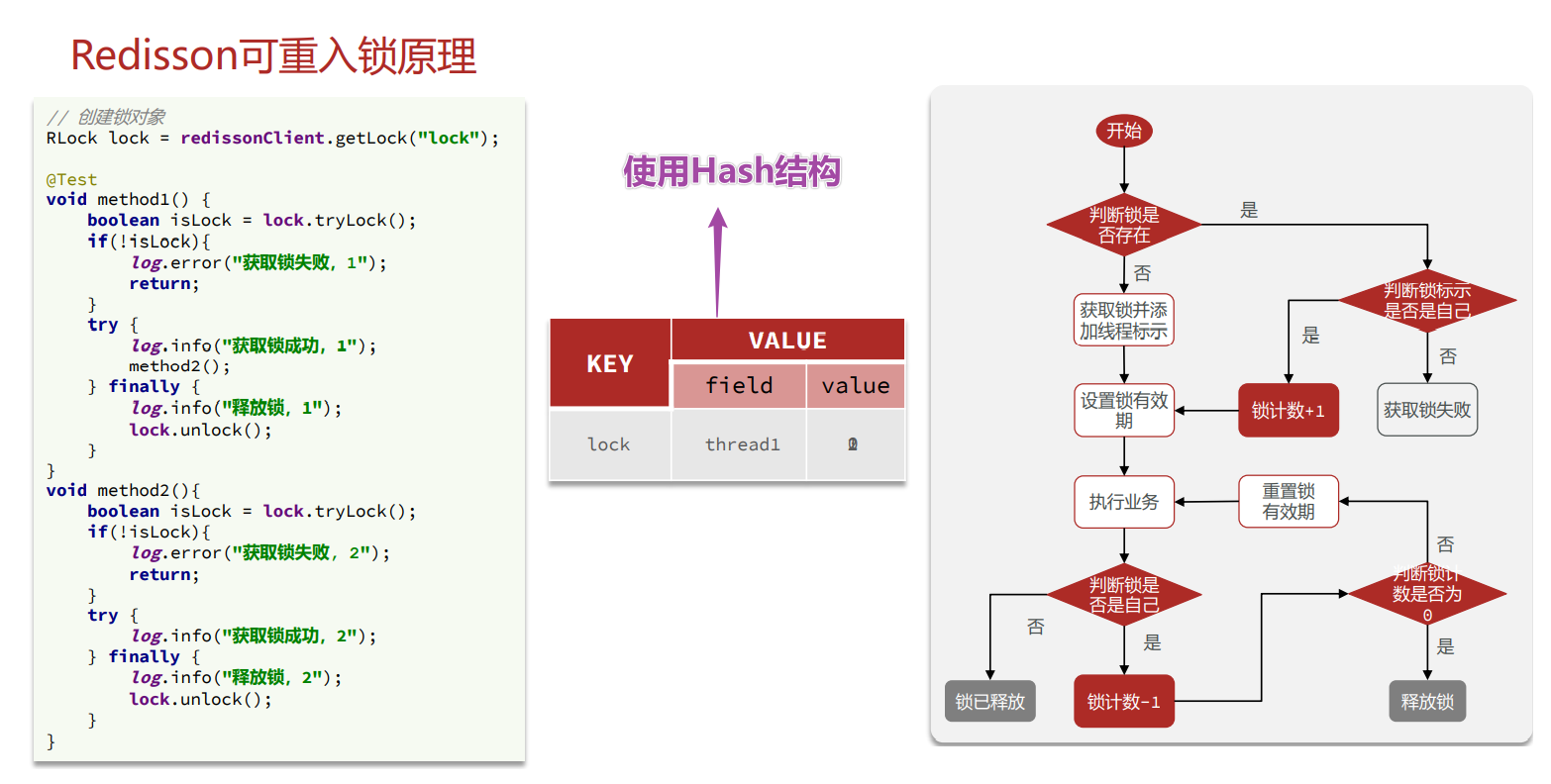
Redisson可重入锁问题
原理:
使用Lua脚本实现 — 获取锁
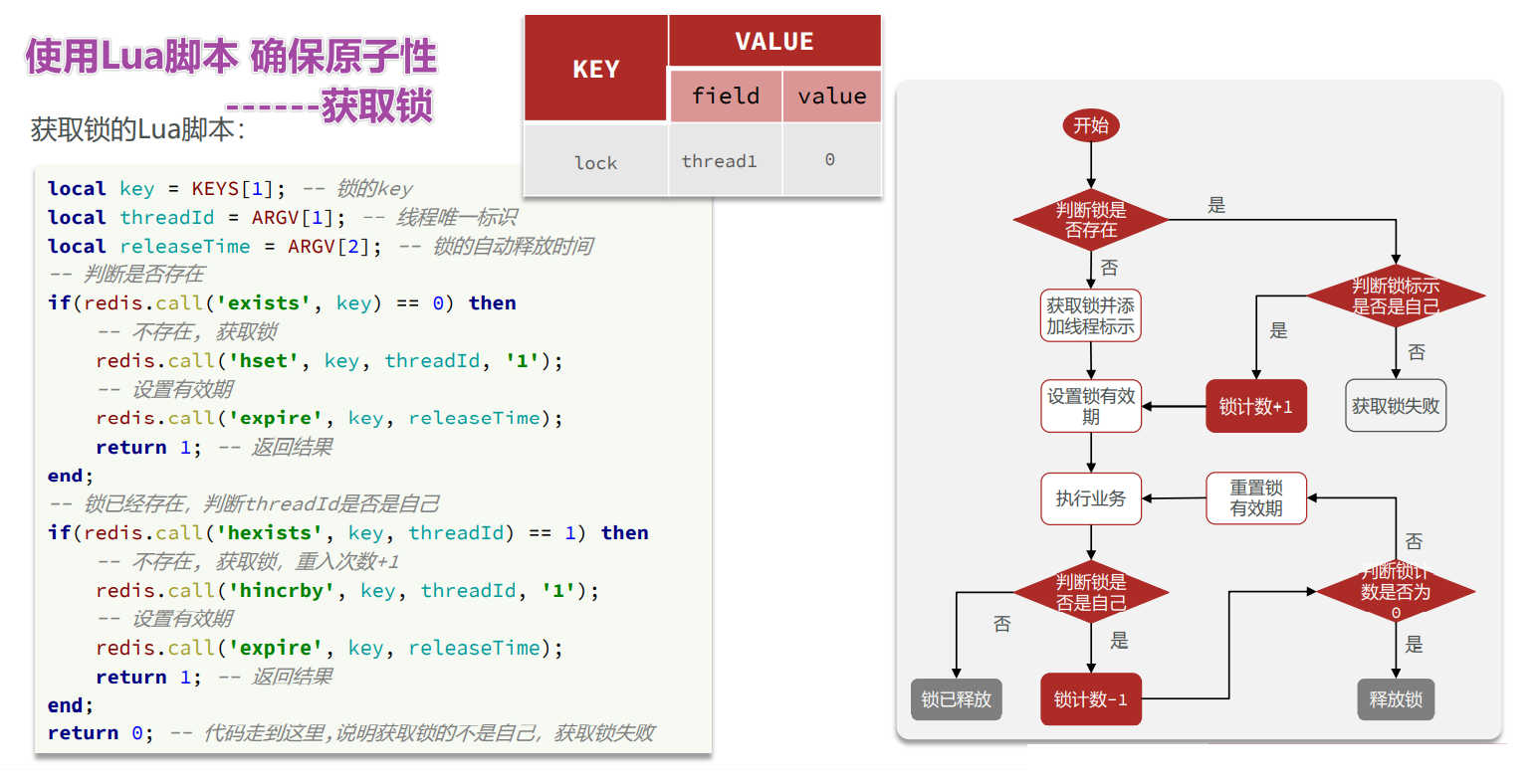
源码:
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) { |
使用Lua脚本实现 — 释放锁
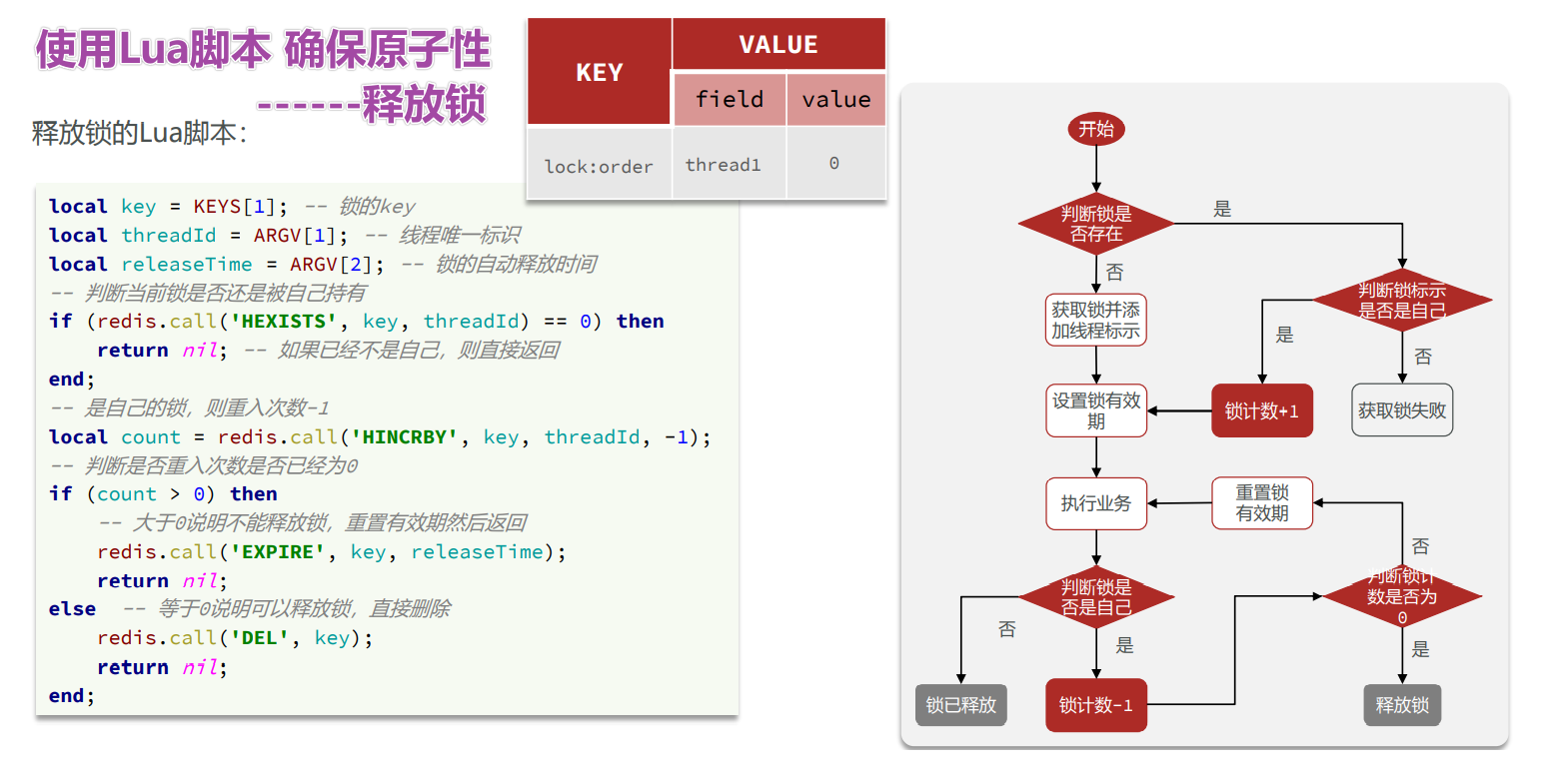
源码:
protected RFuture<Boolean> unlockInnerAsync(long threadId) { |
可重试–WatchDog机制
源码jiji看 jiji分析
超时释放–发布订阅/信号量
源码jiji看 jiji分析
Redisson分布式锁的原理
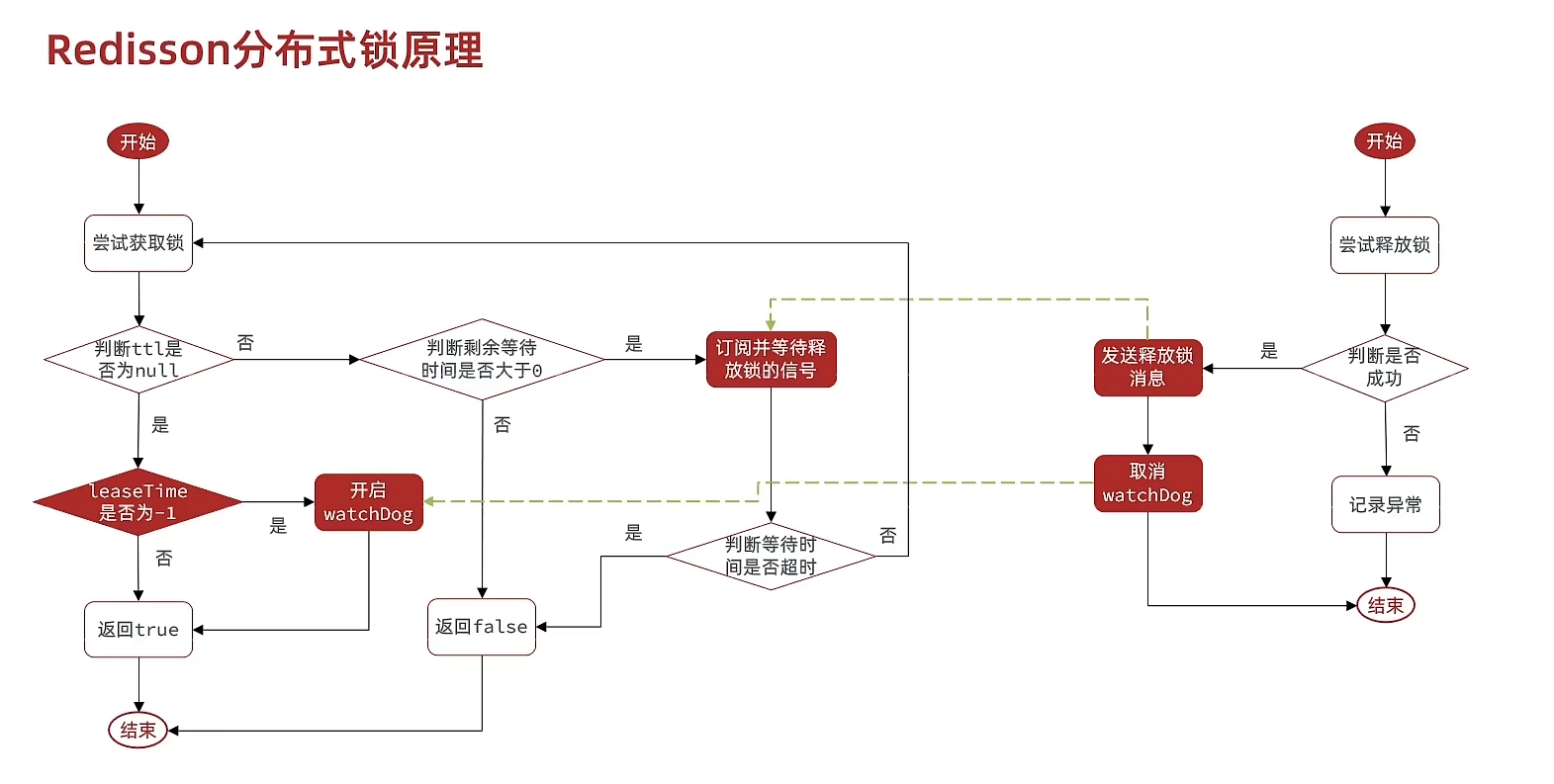
Redisson分布式锁原理:
- 可重入:利用hash结构记录线程id和重入次数
- 可重试:利用信号量和PubSub功能实现等待、唤醒,获取 锁失败的重试机制
- 超时续约:利用watchDog,每隔一段时间(releaseTime / 3),重置超时时间
Redisson主从一致性问题
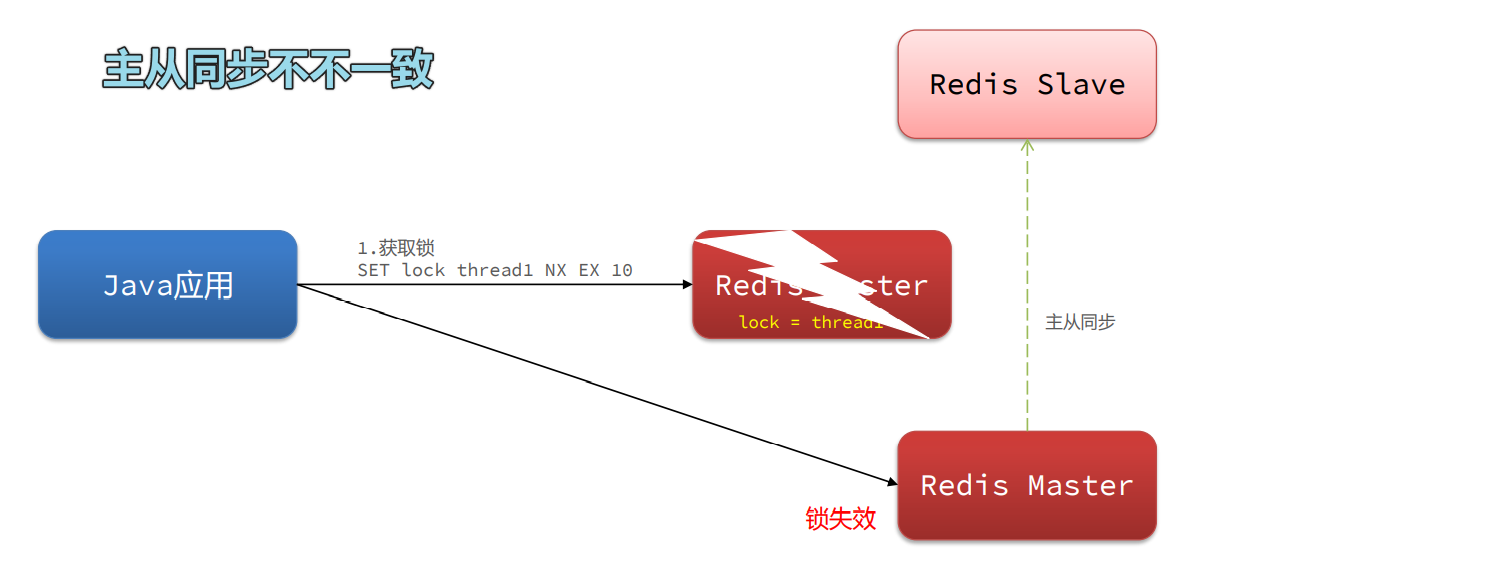
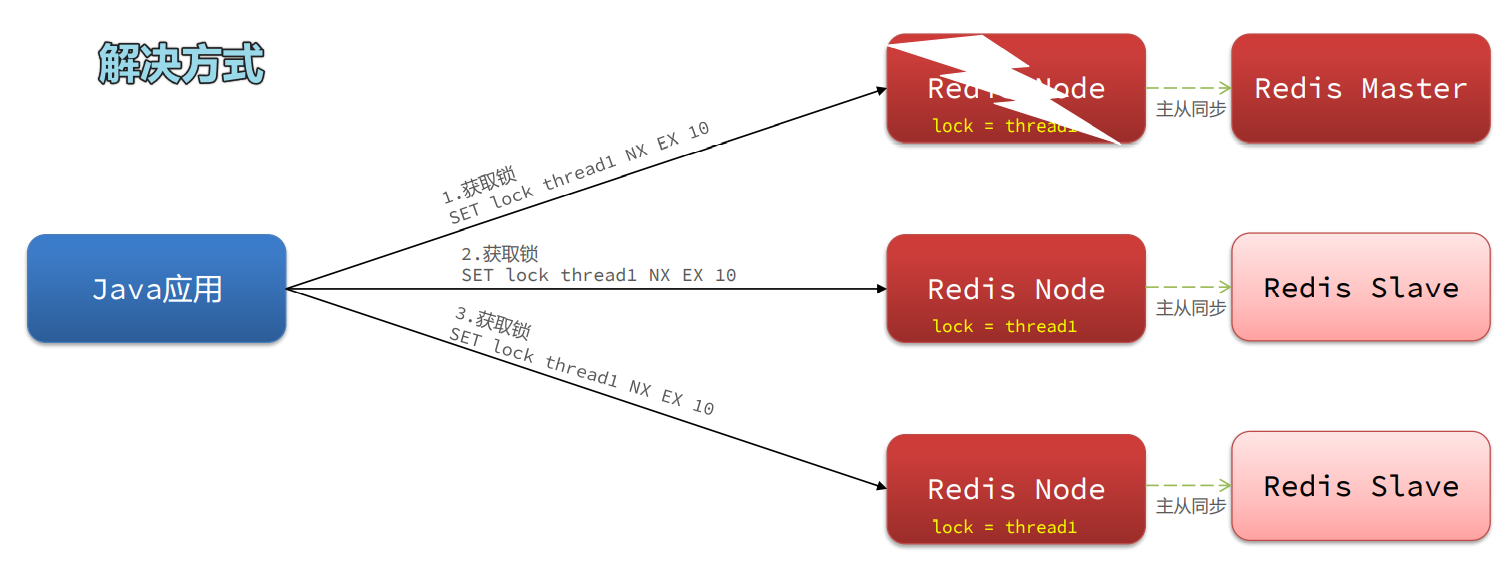
使用:
RedissonConfig
package com.ayaka.config; |
RedissonTests
package com.ayaka; |
总结
总结
1)不可重入Redis分布式锁:
原理:利用setnx的互斥性;利用ex避免死锁;释放锁时判 断线程标示
缺陷:不可重入、无法重试、锁超时失效
2)可重入的Redis分布式锁:
原理:利用hash结构,记录线程标示和重入次数;利用 watchDog延续锁时间;利用>信号量控制锁重试等待
缺陷:redis宕机引起锁失效问题
3)Redisson的multiLock:
- 原理:多个独立的Redis节点,必须在所有节点都获取重入锁,才算获取锁成功
- 缺陷:运维成本高、实现复杂
这样就就觉了分布式锁的问题
但是,还可以继续优化:
Redis解决 [MQ] [消息队列]
秒杀业务的优化
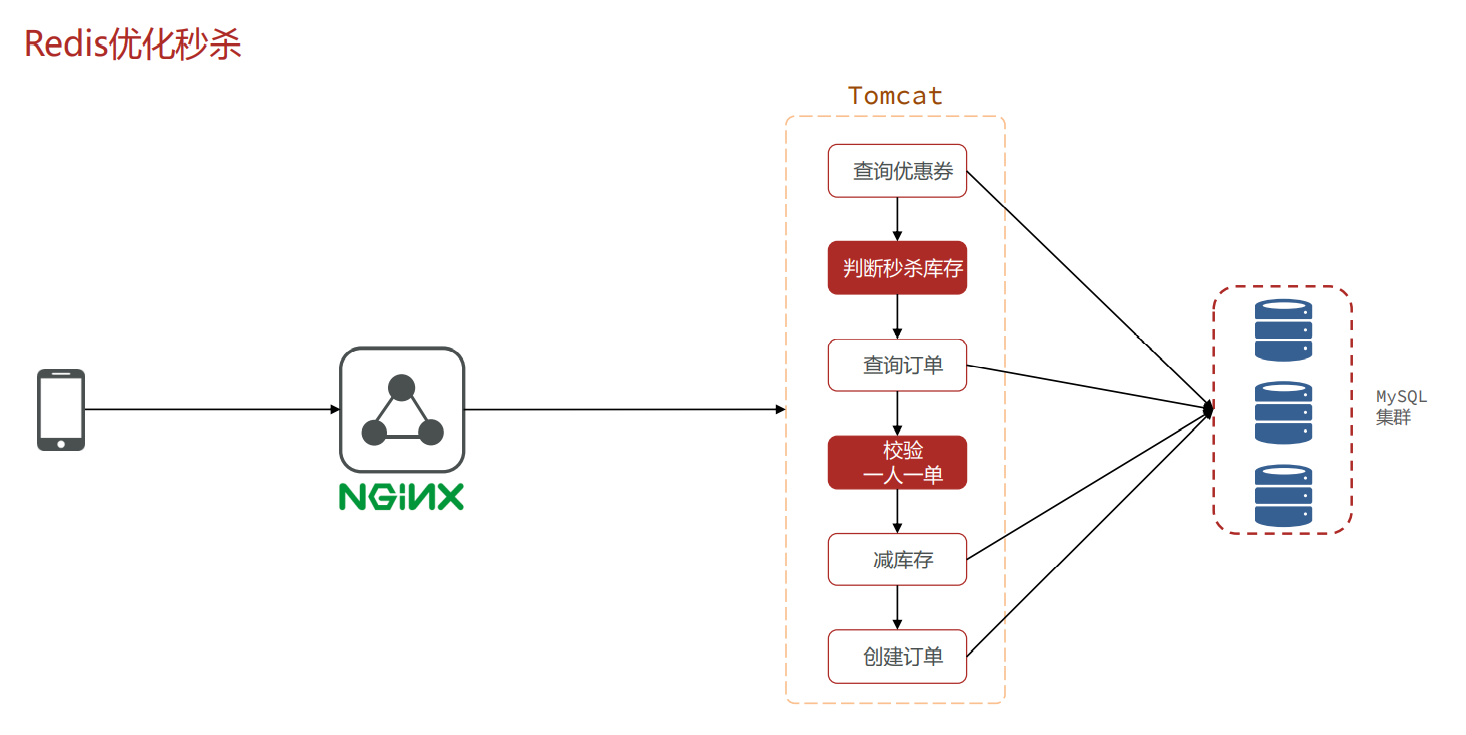
改进方案:
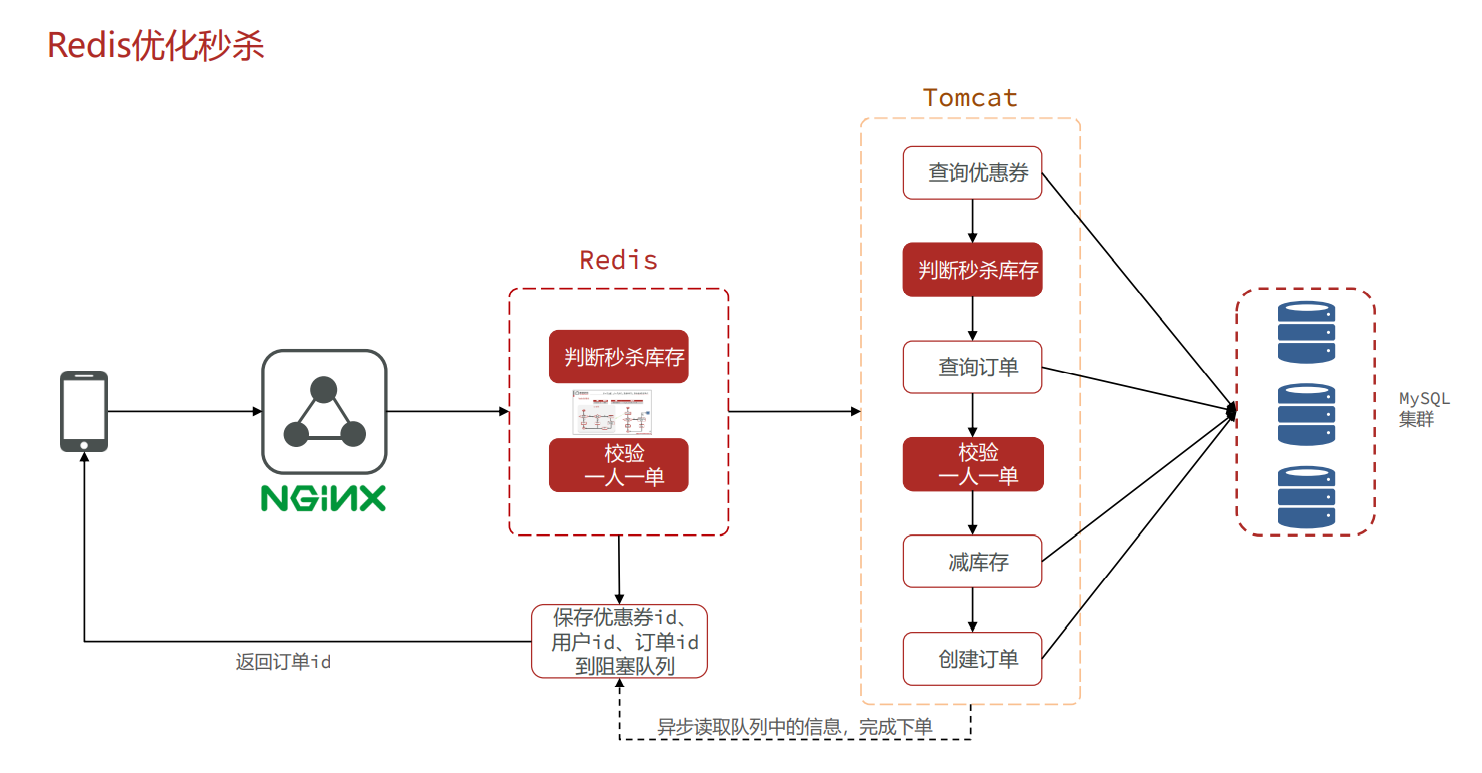
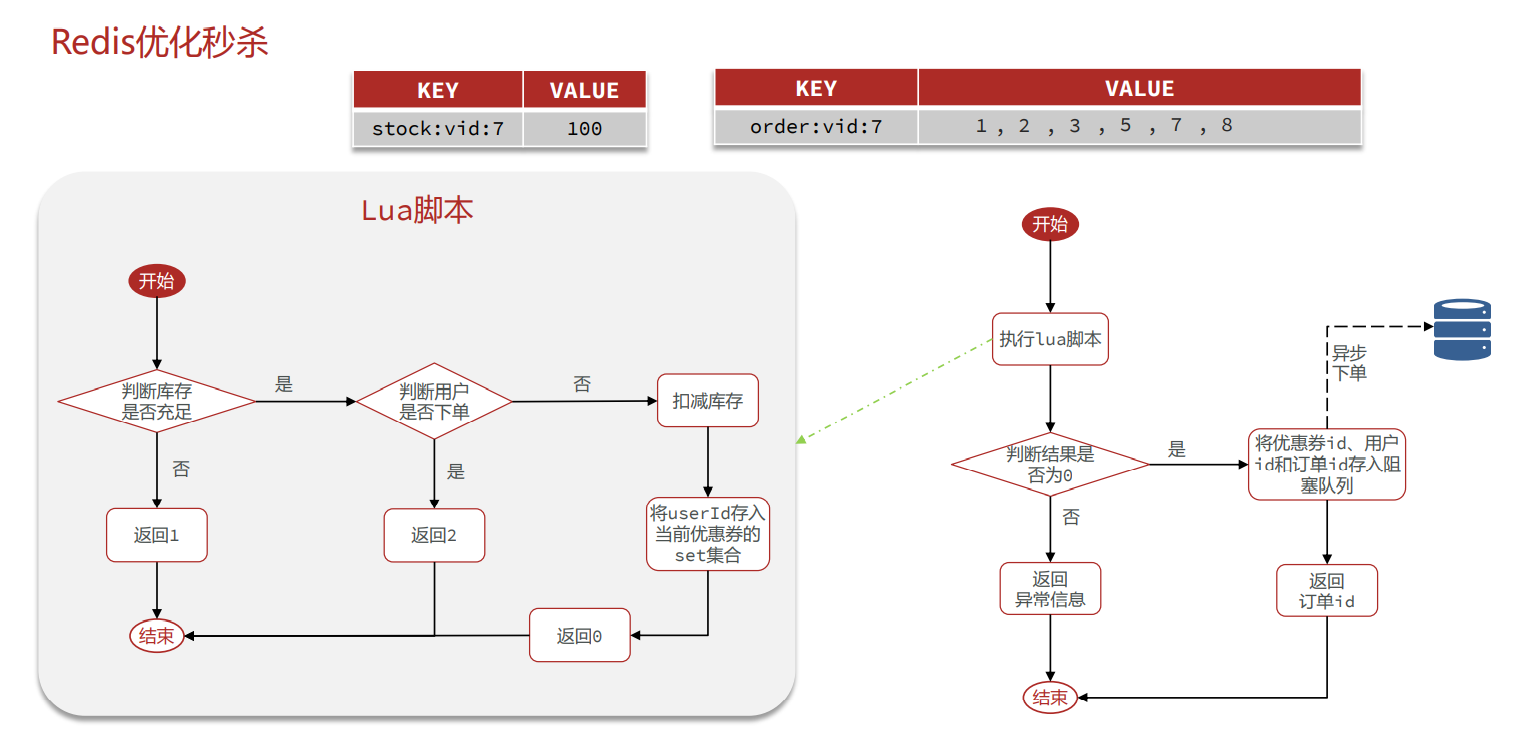

Redis 解决消息队列效果并不好 这里就不实现了 还dai是带MQ的技术去解决 RabbitMQ…
Redis解决 [点赞] [排行榜]
分析 与 问题
Redis类型的选择:
- 一个用户不能重复点赞 – 集合元素不可重复
- 点赞榜 Top5 需要排序 – 集合需要排序 最终选出前5个数据 || Top5(最先点赞的前5人)
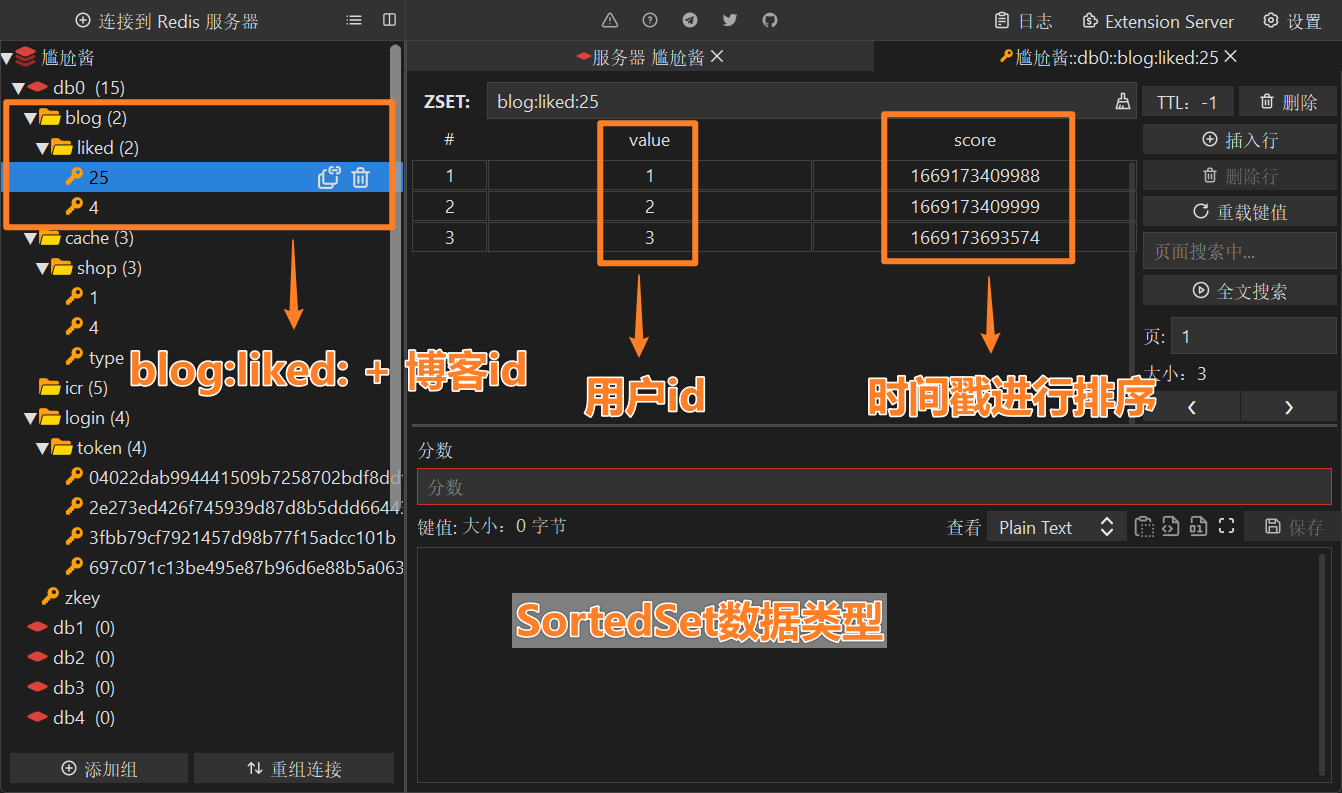
所以 选择了 SortedSet 数据类型
- key :
blog:liked: + 博客id - member:
用户id - score:
时间戳
SorteddSet 要用的的命令
添加成员 — 新增点赞

- reids命令:
zadd blog:liked:博客id 用户id 时间戳 - java命令:
stringRedisTemplate.opsForZSet().add(key,userId,System.currentTimeMillis());
判断是否为该成员 — 判断该用户是否为该博客点赞过

- reids命令:
zscore blog:liked:博客id 时间戳返回部位 nil 为该成员 - java命令:
Double isMemberScore = stringRedisTemplate.opsForZSet().score(key, userId);不为 null 为该成员
按分数顺序查询成员 — 实现点赞 Top5 功能

- reids命令:
zscore blog:liked:博客id 时间戳返回部位 nil 为该成员 - java命令:
Set<String> range = stringRedisTemplate.opsForZSet().range(key, 0, 4);
几个坑:
数据库问题:
/** |
根据博客id 获取点赞排行榜前 5 名
有一个坑:
select * from tb_user where id in(3,2,1); 的查询结果顺序 是 1 2 3
select * from tb_user where id in(3,2,1) order by field(id,3,2,1)
这样才能保证按给定的顺序查询
这里依然有个坑!!
当未有用户点赞时 :SQL语句:SELECT * FROM tb_user WHERE (id IN ()) order by field(id,)语法错误
解决方法 :提前判断
if (ObjectUtil.isEmpty(ids)){ |
空指针异常
//判断当前用户是否为当前博客点赞 |
用户未登录 会报空指针异常 提前判断一下
同一用户多地登录 并发安全问题 TODO: T.T
更多异常 TODO: T.T
库表设置
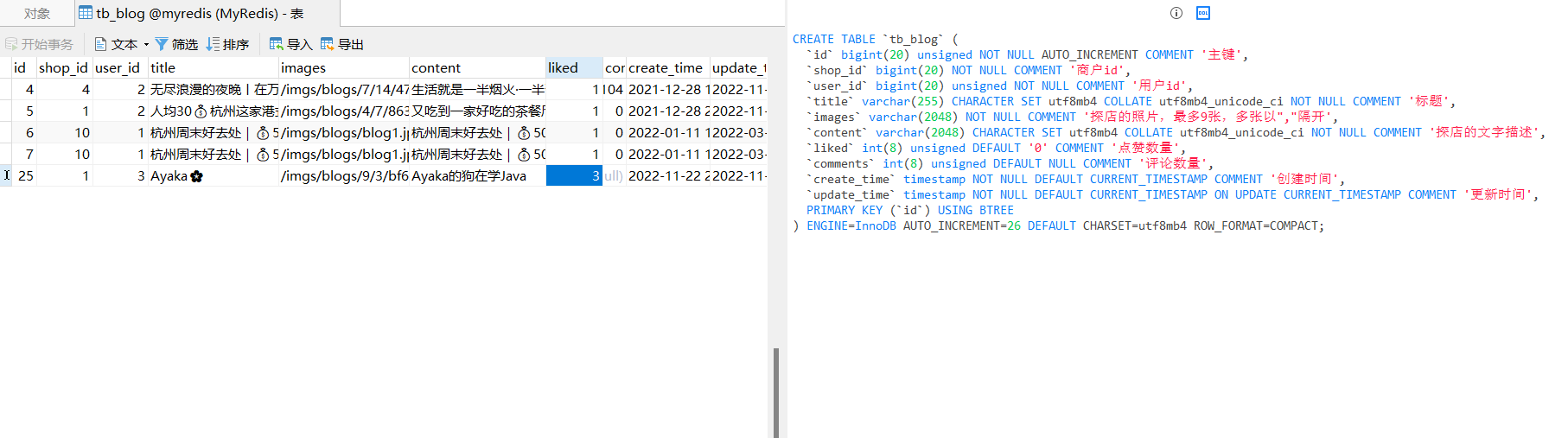
CREATE TABLE `tb_blog` ( |
实体类
package com.ayaka.entity; |
BlogController
package com.ayaka.controller; |
BlogServer
package com.ayaka.service.impl; |
Redis的效果
Redis解决 [关注] [共同关注]
分析
单纯的关注 取消关注功能 只用数据库就行
查看共同关注
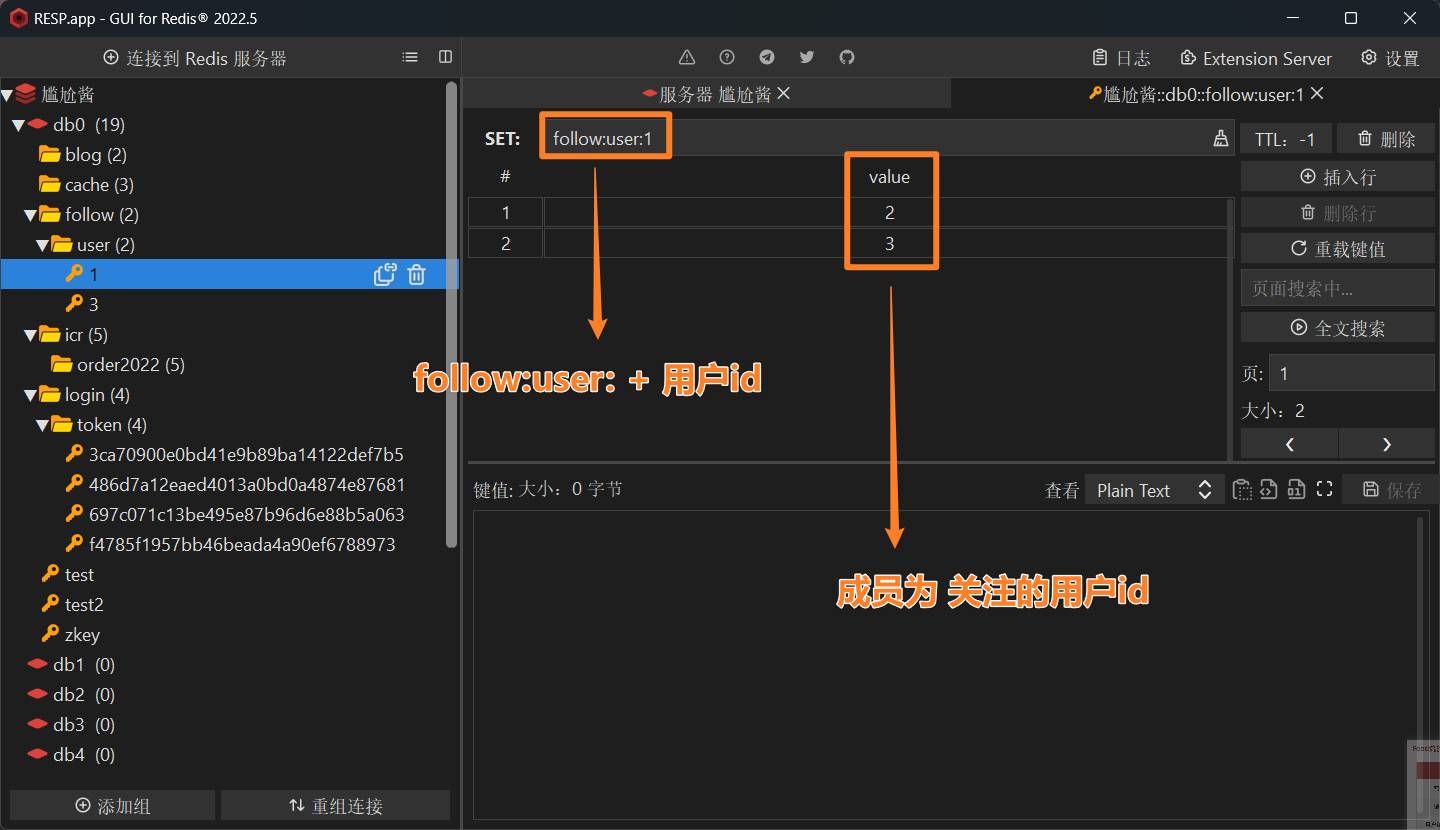
Redis数据类型选择 Set类型
- key :
follow:user: + 用户id - member:
关注用户的id
Set类型 有一个命令可以查询 诺干个key的交集

- reids命令:
sinter follow:user:3 follow:user:6用户id:3 和 用户id:6 的共同关注 - java命令:
stringRedisTemplate.opsForSet().intersect(key1,key2);
库表设计
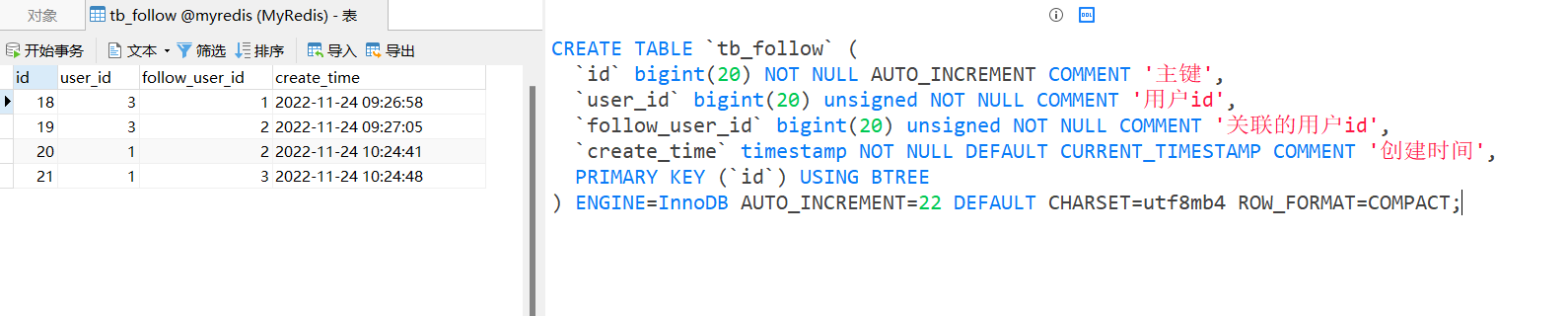
CREATE TABLE `tb_follow` ( |
实体类
package com.ayaka.entity; |
FollowController
package com.ayaka.controller; |
FollowService
package com.ayaka.service.impl; |
Redis效果
Redis解决 [推送] [Feed流]
Feed流
关注推送也叫做Feed流,直译为投喂。为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息。


Feed流的模式
Feed流产品有两种常见模式:
Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
- ➢ 优点:信息全面,不会有缺失。并且实现也相对简单
- ➢ 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
智能排序[Rank]:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
- ➢ 优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
- ➢ 缺点:如果算法不精准,可能起到反作用
Feed流 Timeline模式
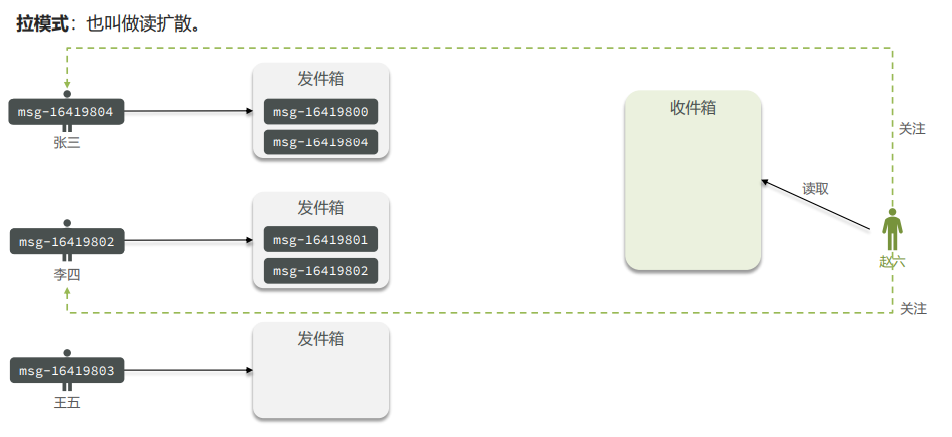
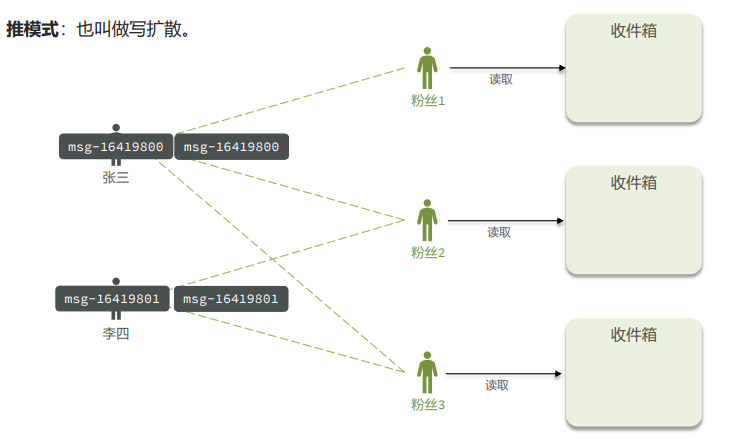
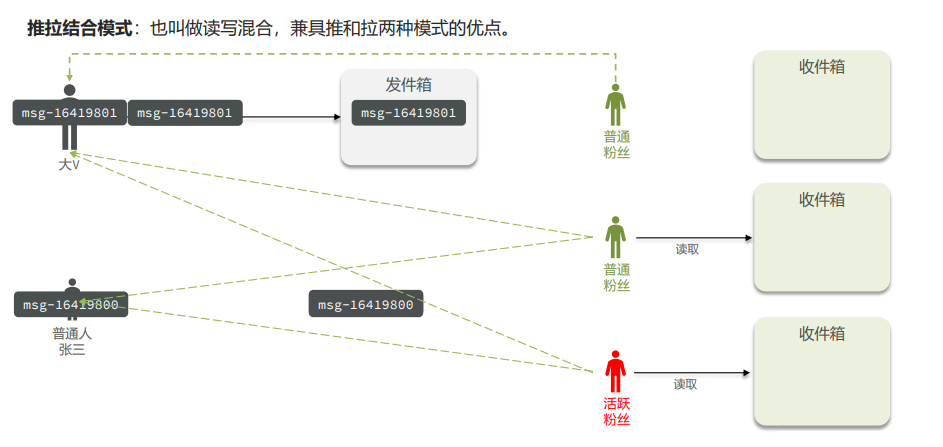
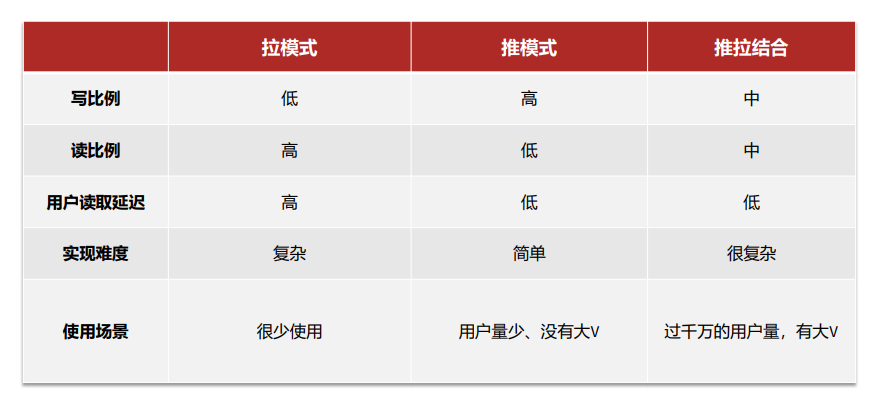
Feed流,Timeline的模式,该模式的实现方案有三种:
- 拉模式
- 推模式
- 推拉结合
拉模式
推模式
推拉结合
Feed流的实现方案
案例分析
案例要求:
点击关注后,会查询出该用户关注的其他用户的博客,按时间降序排列,滚动分页。
使用 Timeline模式 的 推模式
接口:
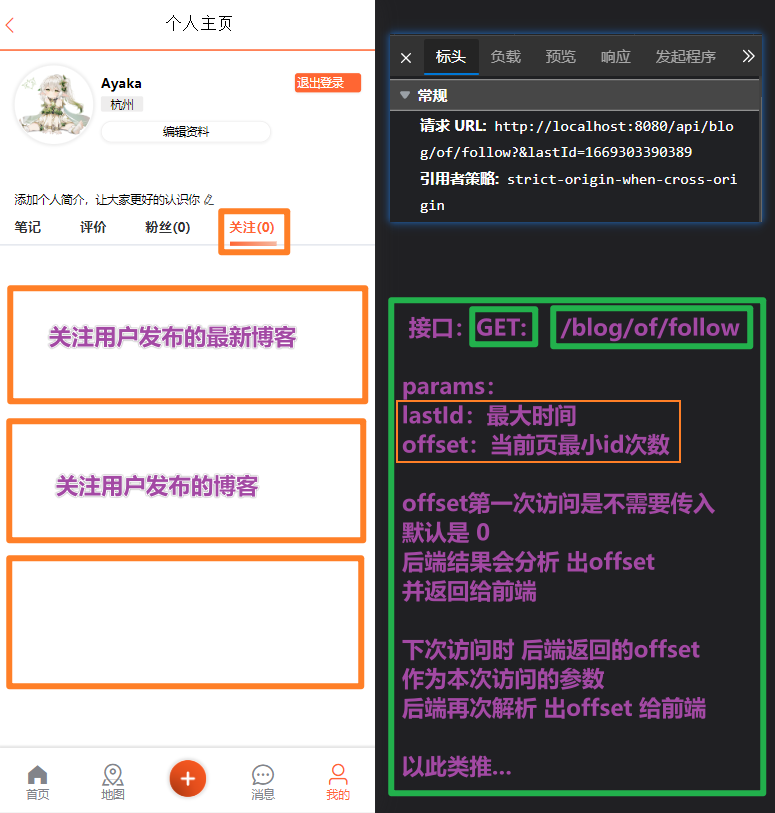
Redis的类型选择
使用 SortedSet 数据类型
- key :
feed:user: + 用户id - member:
关注用户的博客id (被关注者发布的博客) - score:
博客发布的时间戳
当一个用户发布博客时被关注者发布的博客id,
根据当前用户,查询所有的关注者,
得到所有关注者的id 即: feed:user: + 用户id 后,
保存到 Redis 当中:
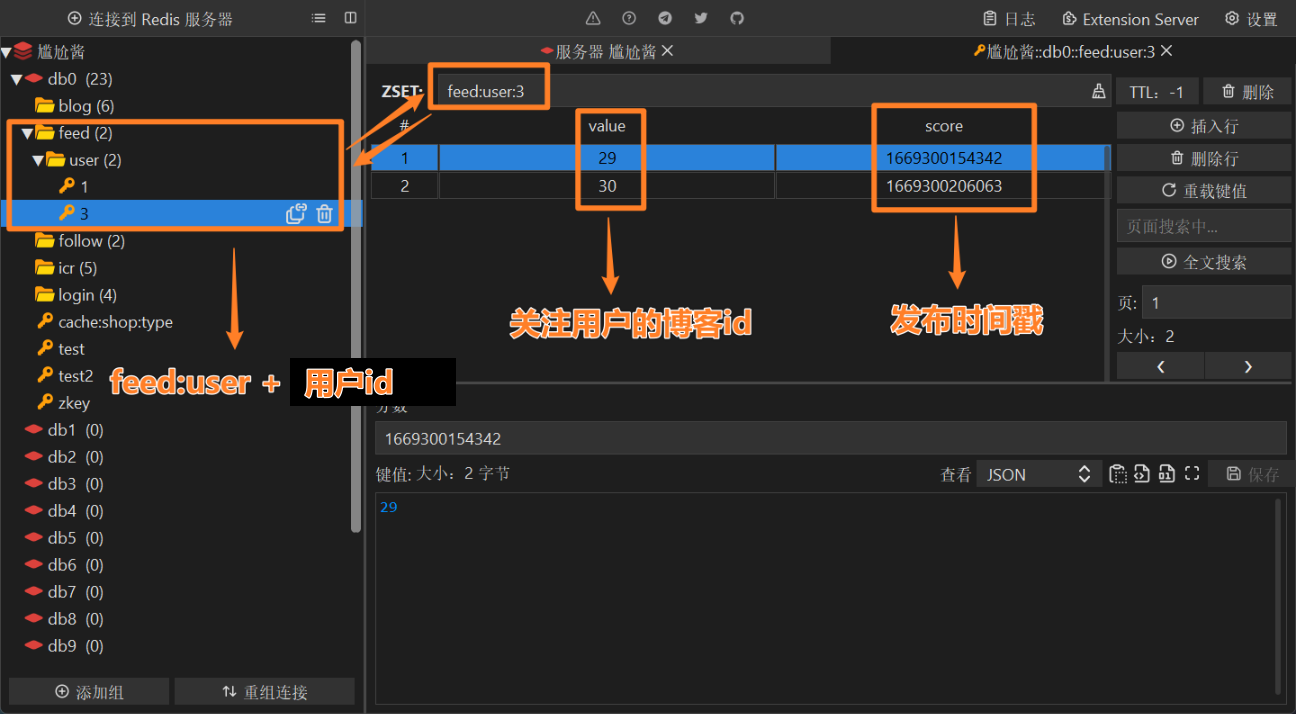
要使用的命令
发布订阅时,向用户推送,被关在的用户会保存该博客id

- reids命令:
zadd feed:user:3 5 521id为x的用户,在521时刻,发布了id为5的博客,并推送给了id为3用户。 - java命令:
stringRedisTemplate.opsForZSet().add(key,blog.getId().toString(),System.currentTimeMillis());
用户获取订阅的内容,可以进行分页

reids命令:
ZREMRANGEBYSCORE follow:user:5 最大时间戳 0 withscores limit 0 3首次reids命令:
ZREMRANGEBYSCORE follow:user:5 上次最小时间戳 0 withscores limit 上次最小时间戳次数 3下次java命令:
stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, maxTime, offset, 2);返回一个
ZSetOperations.TypedTuple<String>>```java
//TypedTuple接口
@Nullable
V getValue(); //成员@Nullable
Double getScore(); //分数
---
### ===开始实现===
---
### 返回给前端实体
用于分页擦寻后 返回的数据
```java
package com.ayaka.dto;
import lombok.Data;
import java.util.List;
@Data
public class ScoreResult {
//分页后的数据
private List<?> list;
//最小时间戳 用于下次请求分页
private Long minTime;
//最小时间戳出现的次数 用于下次请求分页的偏移量
private Integer offset;
}
[发布] 信息的发布
保存博客 并 实现推送功能
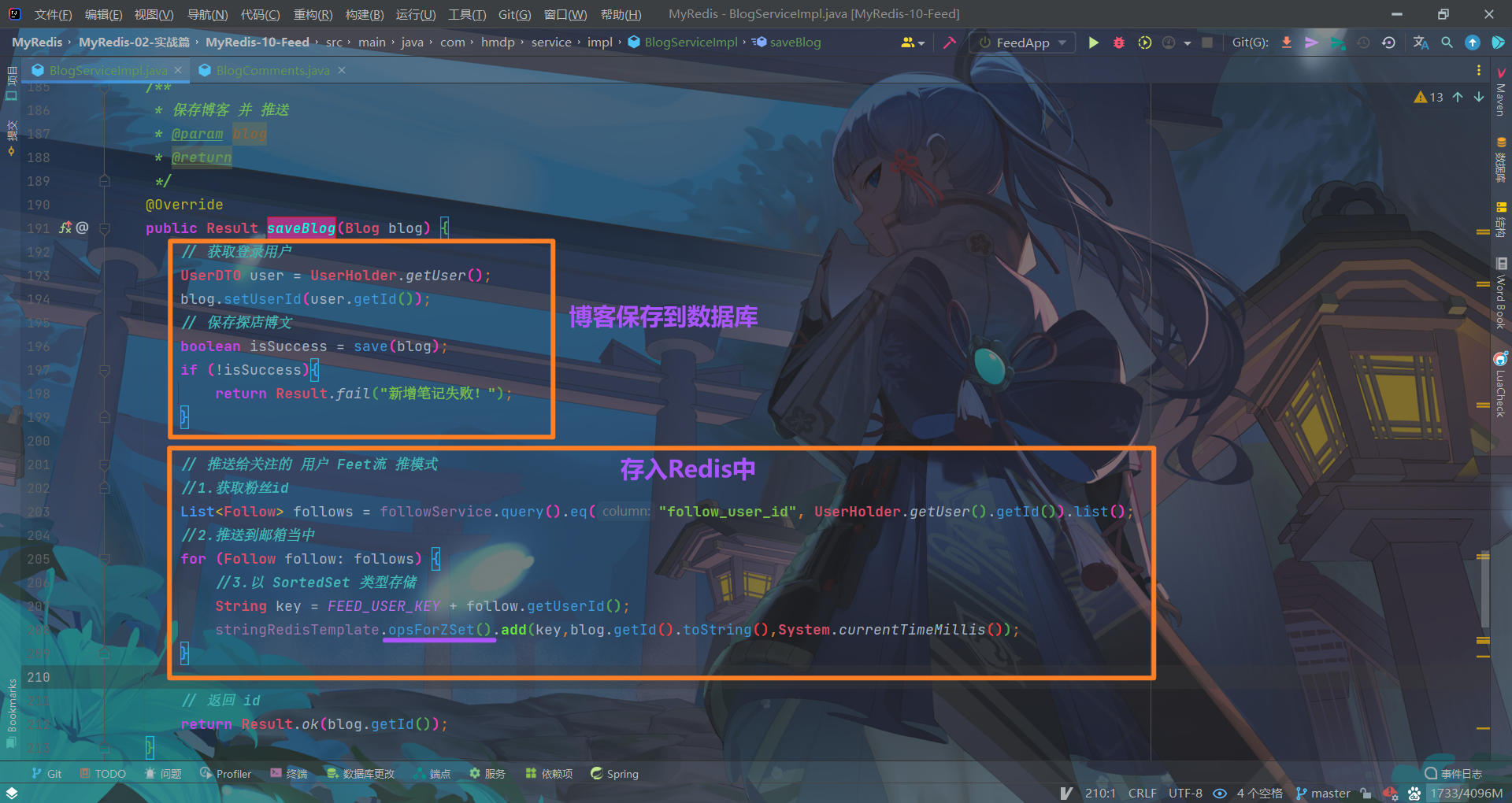
/** |
[接收] 滚动分页查询的实现
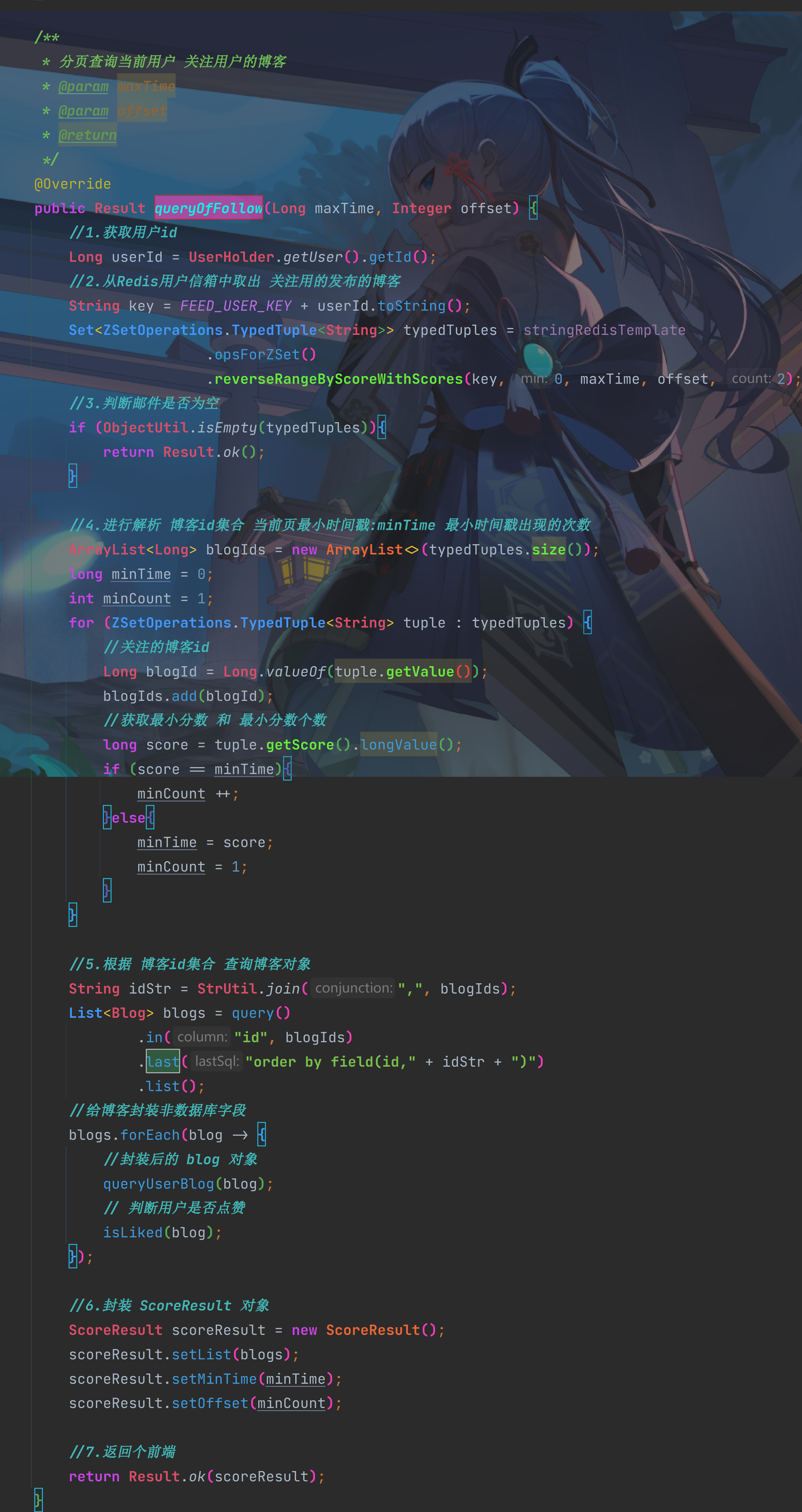
/** |
Redis解决 [地理] [附近店铺]
分析
附近商户搜索
使用GEO数据类型
GEO就是Geolocation的简写形式,代表地理坐标。
Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。
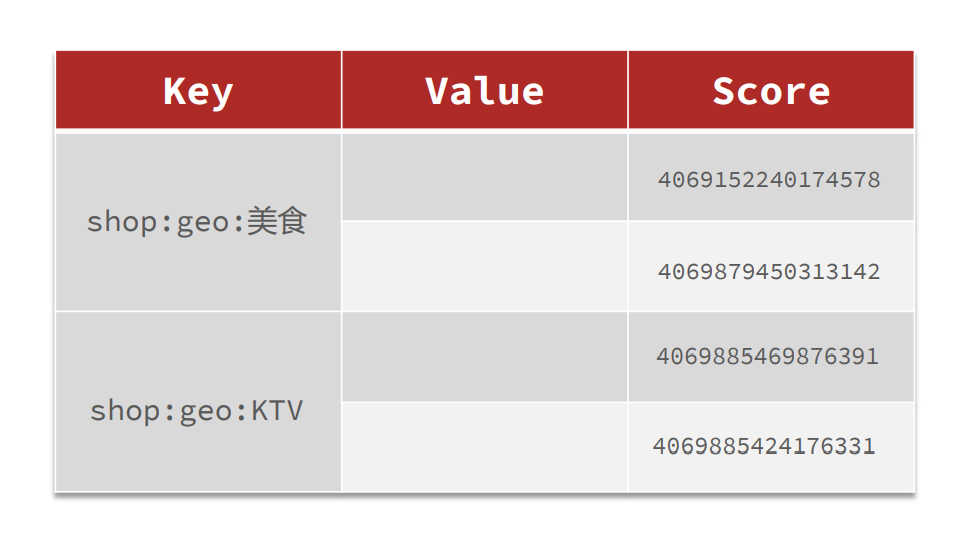
要使用的命令
添加地理坐标

获取相对 位置/距离

接口
/** |
添加地理坐标

package com.ganga; |
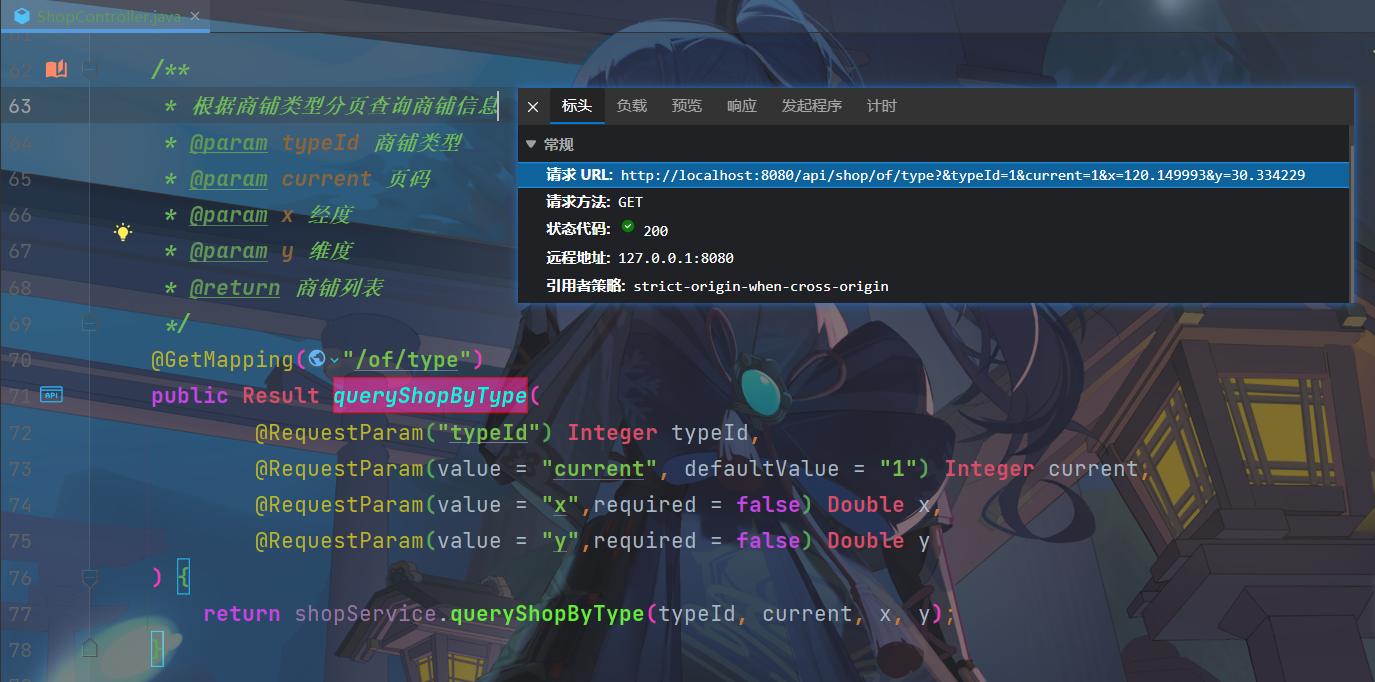
分页查询
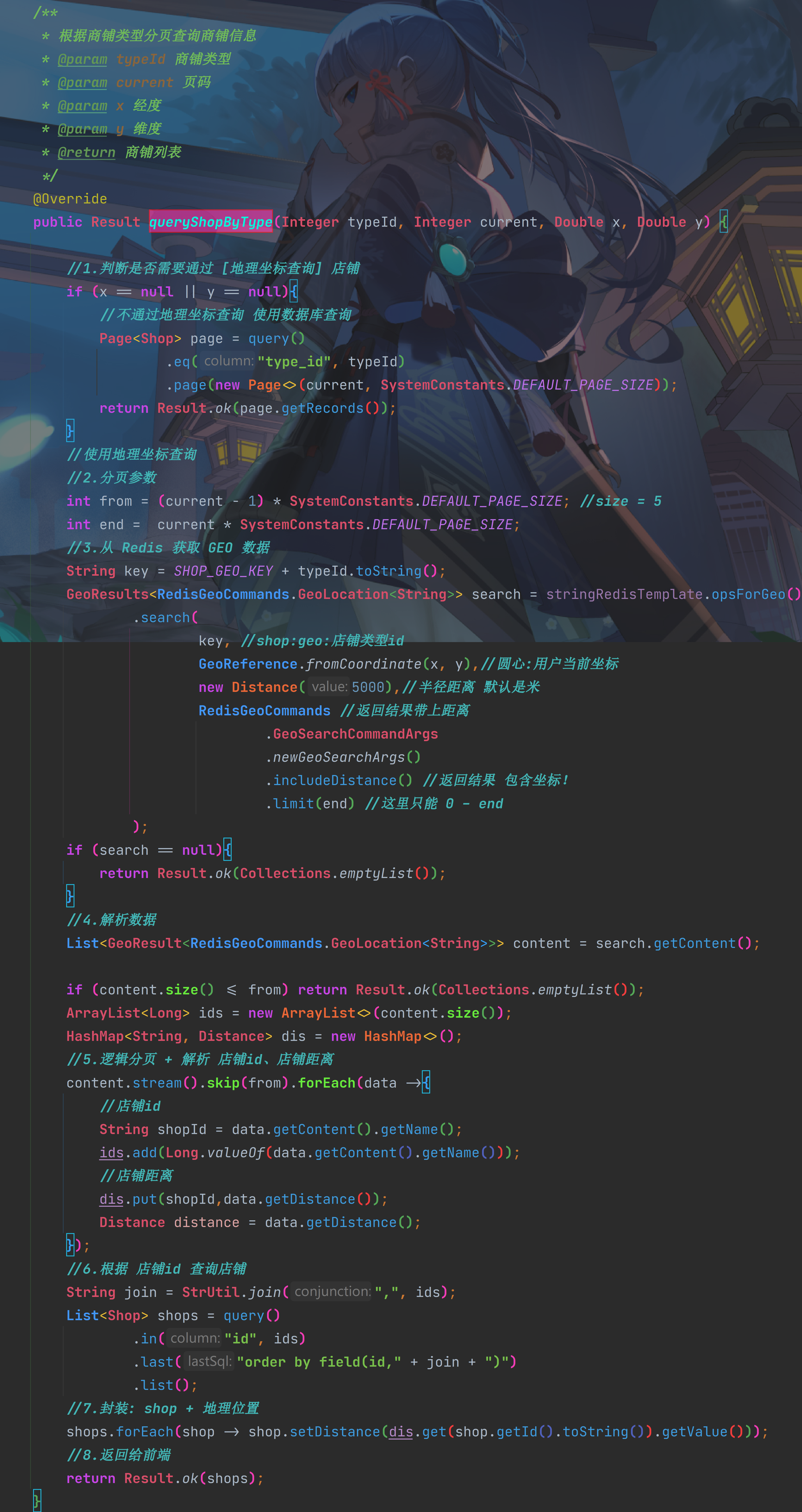
/** |
Redis存储
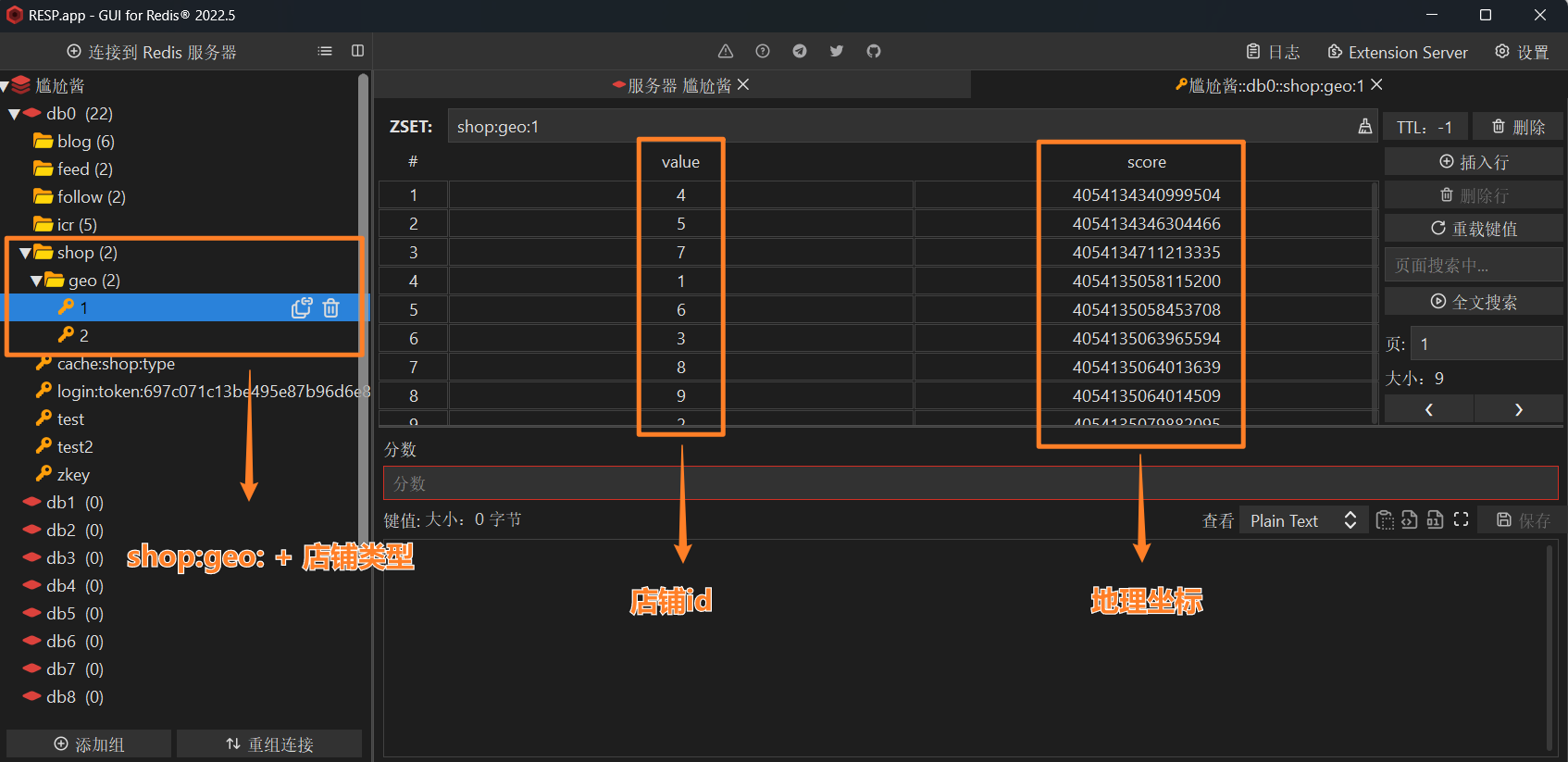
实现效果
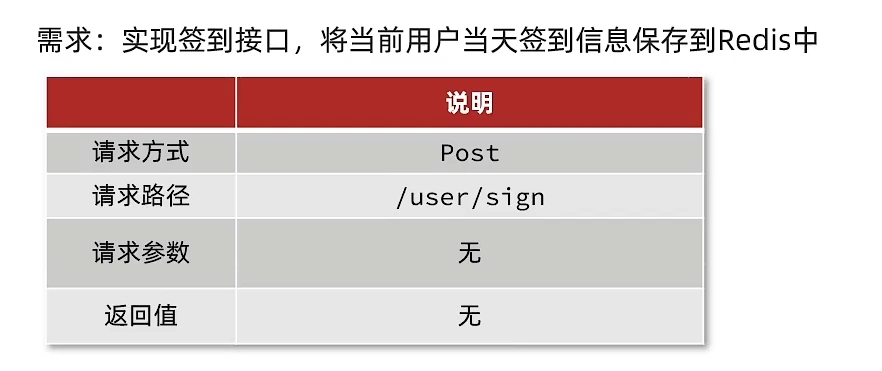
Redis解决 [签到] [BitMap]
案例分析
要求
如果使用数据库记录
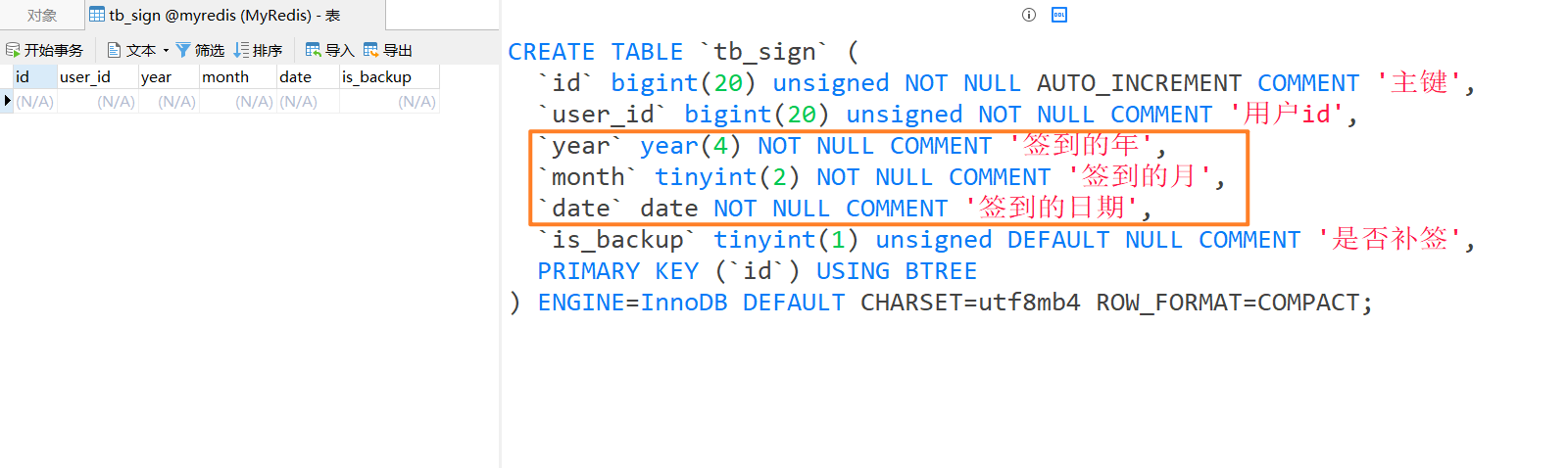
CREATE TABLE `tb_sign` ( |
假如有1000万用户,平均每人每年签到次数为10次,
则这张表一年的数据量为 1亿条 每签到一次需要使用(8 + 8 + 1 + 1 + 3 + 1)共22 字节的内存,
一个月则最多需要600多字节
使用 BitMap数据结构 –位图
把每一个bit位对应当月的每一天,形成了映射关系。
用 0 和 1 标示业务状态,这种思路就称为位图
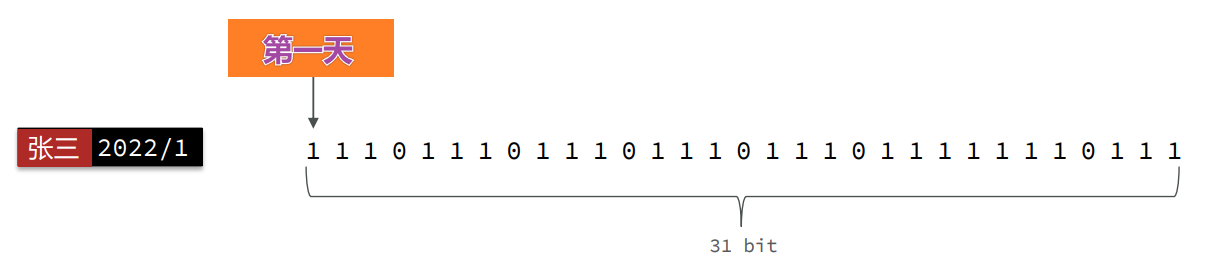
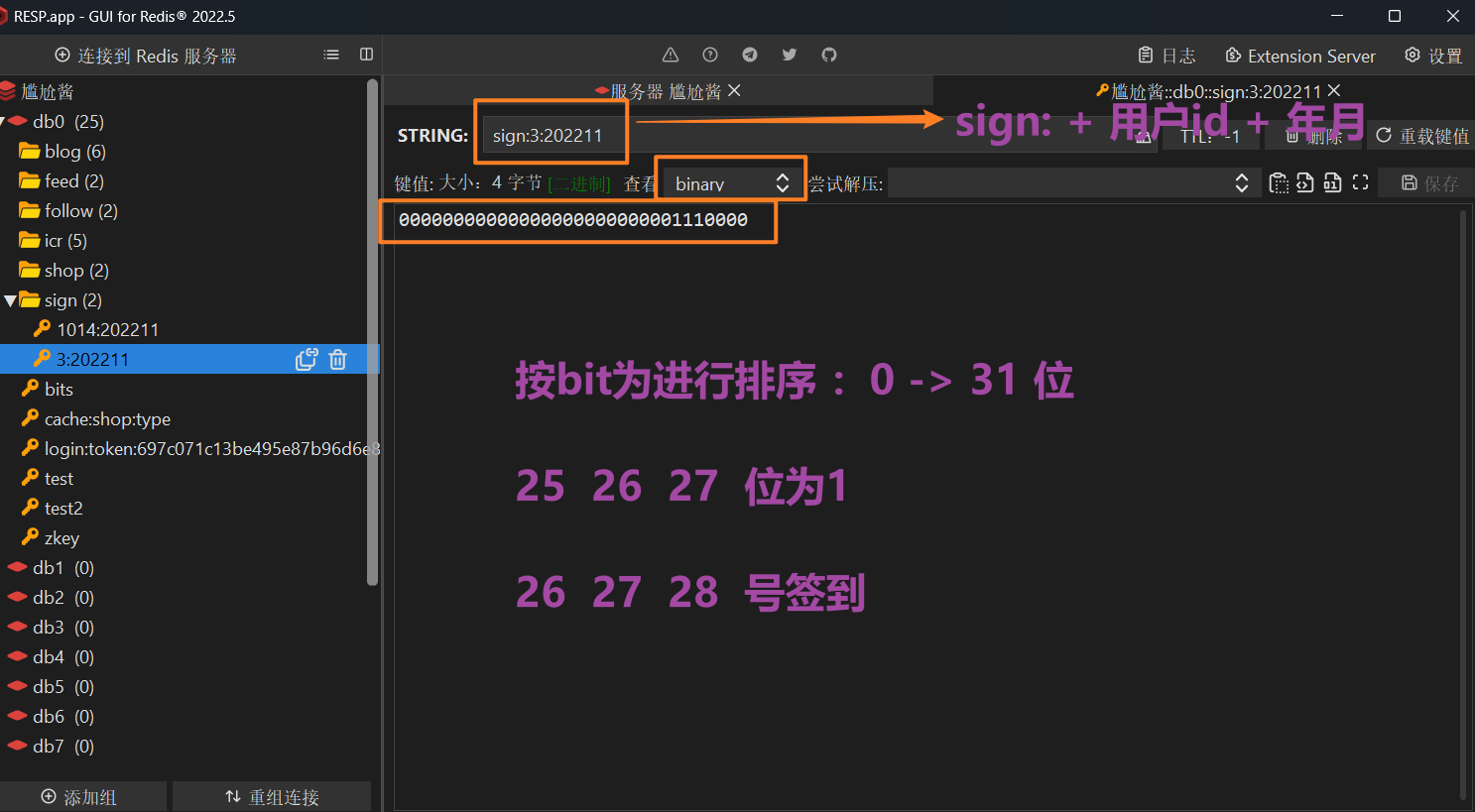
要使用的命令
解决方案
签到好解决,是需要使用 **setbit sign:用户ID:年月 当月几号-1**即可。
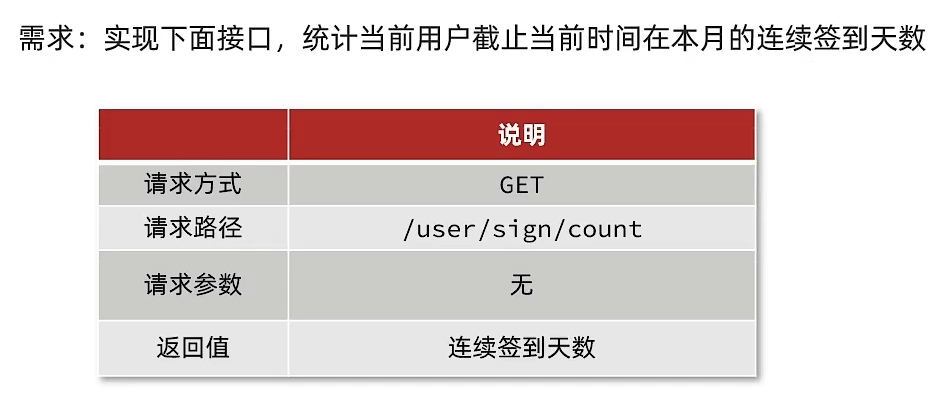
判断 连续签到 [从最后一次签到开始向前统计,直到遇到第一次未签到为止,计算总的签到次数,就是连续签到天数。]

实现:
int count = 0; |
前端控制器

/** |
业务实现
/** |
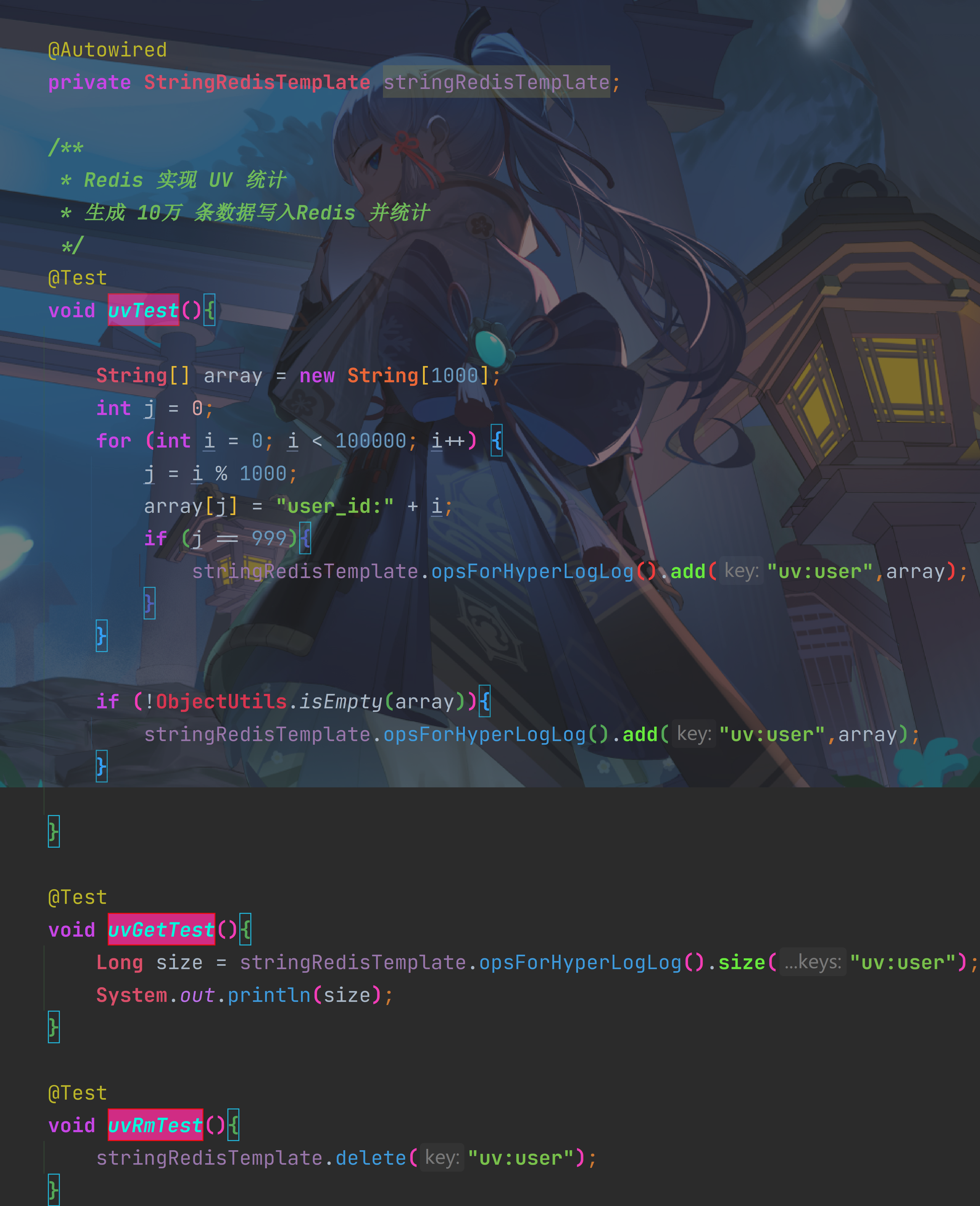
Redis解决 [统计] [UV统计]
HyperLogLog用法
首先我们搞懂两个概念:
- UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次 访问该网站,只记录1次。
- PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则 记录多次PV。往往用来衡量网站的流量。
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。
但是如果每个访 问的用户都保存到Redis中,数据量会非常恐怖
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。
相关算法 原理大家可以参考:https://juejin.cn/post/6844903785744056333#heading-0 Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结 果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。
Redis实现 UV统计
package com.ganga; |
TODO:
 微信
微信 支付宝
支付宝





![MyBatis-Plus模板生成🌸[新版]VS[旧版]](https://ayaka-icu-oss.oss-cn-beijing.aliyuncs.com/img/cat/cat19.png)
